

Kyle Simpson (@getify) is a JavaScript Systems Architect from Austin, TX. He focuses on JavaScript, web performance optimization, and "middle-end" application architecture. If something can't be done in JavaScript or web stack technology, he's probably bored by it. He runs several open-source projects, including LABjs, HandlebarJS, and BikechainJS. Kyle is a Senior Architect for client and server side JavaScript for appendTo, LLC.
Do these pants make me look fat?
Every time an HTTP request is made or an HTTP response is returned, in addition to the main body content, there’s a string of Headers (key/value pairs) which contain meta-information about the HTTP packet. Headers tell the message recipient about the originator, the nature of the message content (including how it should be decoded/interpreted), how long to consider the message as valid, etc.
If you’re interested, take a glance at the list of valid, defined HTTP Request and Response Headers.
When a browser makes an HTTP request, it sends along a slew of request headers. Take a look at what some request headers look like:

(yeah, I’m using IE9 beta for these screenshots. so what!?)
And here’s the response headers from that same page-view:

Some of this information is really important, but there’s also a lot of bloated waste in these headers, in both directions. The hidden header information in all our HTTP requests and responses is silently weighing down our transmissions, wasting bandwidth, clogging the pipes, and slowing both message creation and message reading.
Headers can comprise anywhere from 200-1000 (or more!) bytes of the total message size. For small messages (like a basic CSS file for instance), This could be 30-50% of the message’s weight, or even worse!
We’ll discuss some of these headers to help you identify which ones you can trim down to improve your website’s performance. Some of the suggestions I make will be practical things you can actually change now, and some of them are future-thinking suggestions about things that servers and browsers could (and should) be smarter about, giving us more control to trim the fat where necessary.
Request Headers
The “Request” request header is obviously important; that’s how the server knows what resource/file is actually being requested. Similarly, “Host” is how the request message gets routed to the correct server, and how the server knows which site (if it hosts several on the same IP — called Virtual Hosting) should handle the request.
“Accept” and “Accept-Language” are fairly important: they tell the server what type of response is valid and desired by the requesting client (browser). If the server is capable of serving of a document in different document-types, or in a different localization language, these headers tell it which one the requester prefers.
“Referer” is an interesting one. There’s several reasons why “Referer” is useful, but it’s by no means a required field. For analytics purposes, people like to know the “source” of where people are finding links to their site, such as Twitter or search engines. There are also some sites which will only allow free (unauthenticated, unpaid) access to content if you are coming to the page referred by certain sites, like a search engine. Whether such behavior is helpful or annoying is a discussion for another time. The point is, this field has some usefulness for at least the initial page request.
However, the browser will typically send this header along with almost every request, letting the server decide if it wants/needs it or not. This is where such a header can perhaps be wasteful: many browsers will send the “Referer” header for any subsequent resource requests such as CSS files, JS files, images, etc, and will usually (and somewhat strangely) set it to the URL of the main page.
While having a hint to the server that these resource requests actually came from your site might be marginally helpful for preventing “hot-linking” (people linking to your content from their own sites), the net-positive benefits are less definitive than for many other headers. Moreover, this header (like most) can be spoofed by the browser (via browser extensions, etc), so it’s not all that reliable anyway.
Being able to tell the browser not to send such a header for all dependent page resource requests has some potential to reduce size (and thus speed up) such requests. It’s something the browsers should at least consider as a configuration option. Another option is that the server could opt-in with the initial page request’s response headers, requesting the “Referer” header for any subsequent resource requests. Otherwise, the browser would simply not send it. In either case, making “Referer” at most a conditionally-used field will definitely cut back on unnecessary header bloat.
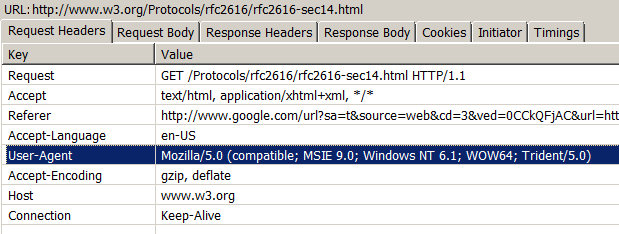
(My User-Agent value is 70 bytes all by itself)
Another request header that has some questionable utility on every single page resource request is “User-Agent”. The “User-Agent” gives various pieces of information (some useful, some not) to the server about the client (browser), including operating system, plugins installed, browser vendor and version, etc. The “User-Agent” string can be be anywhere from 60 to 120 characters (bytes) all by itself, so it’s one of the important ones to lend a careful eye to size-wise.
Just like with “Referer”, the “User-Agent” header is mostly useful for the initial page-request and has some diminished usefulness for subsequent page resource requests. Some servers will read the “User-Agent” and serve different JavaScript or CSS depending on the requesting browser, but this is less common. And it’s similarly unreliable, not only because of spoofing, but because of the extreme variety and instability of the values across the history of browser vendors and versions.
While you might make the case that there’s some value to browser type (and version), certainly things like plugins installed, operating system, etc, are even less relevant to the vast majority of website functionality. For almost exclusively historical reasons (and that slim corner-case usefulness), we are stuffing that field full of wasted information on every single request. If you could change your browser’s “User-Agent” setting to something short like “Microsoft IE9” and you didn’t care about some random site breakage, you could reduce ~60-80 bytes from every single request your browser ever makes.
The action point is not just for browser users, though. This is also a point of advocacy for website developers to not build functionality based on the “User-Agent” field unless it’s absolutely impossible to properly function otherwise. Almost without exception, if you’re having to use the “User-Agent” value in a request’s headers to control behavior, you’re probably doing it wrong and should re-think it, for the benefit of overall web performance optimization. If we as web authors do our part to radically deprecate usage of “User-Agent”, eventually it may be a field browsers can do away with (partially or entirely).
Cookies
This next single request header (“Cookie”) can have a staggering impact on the size of every request. I’m not going to spend a lot of time explaining how cookies work, so if you don’t feel you understand them very well, spend some time right now reading the HTTP Cookie article on Wikipedia.
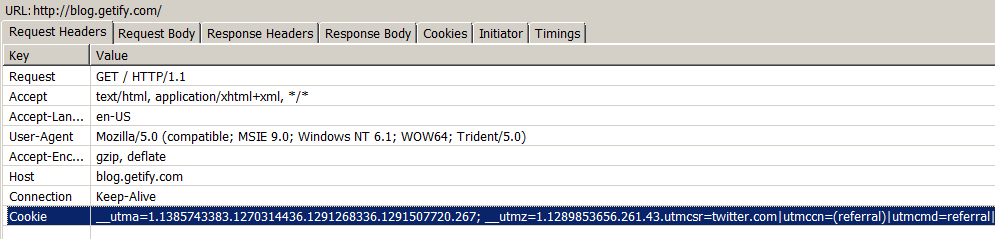
The cookies being sent in this one page request are a mind-blowing 582 bytes, just for that one header and just for one of the many requests that make up a single page-view! Every single other request made to the same domain name will also get all those cookies. If my blog page loads up a couple of CSS files, 5-8 images, and 3 JavaScript files — a total of 14 requests — that’s 8k of extra transmission weight, just for one page load.
Even if the caching is really smartly done, and subsequent page-views only need to make 3 or 4 requests instead of 14, you’re still wasting 2k or more for every page-view. Now scale that up to 10,000 page-views per day. See how quickly those cookies add up?
NOTE: On average, most sites see somewhere from 200-400 bytes from cookies, but 600+ byte cookie sizes are not at all unusual if you use two or more third-party services on your site, like Twitter, Google Analytics, AddThis Social Sharing, Facebook Like Button, etc.
Keep in mind, most of those cookies are not ones that my blog software is directly setting on my domain; most of them (like the __utma stuff) are being set by JavaScript third-party tools like Google Analytics. But the browser doesn’t care, if there’s a cookie set on the domain, it will send it along in every request, no questions asked. You really have to ask yourself: “I get some benefits from analytics, but if it requires so much extra wasted bandwidth to make them work, is it really worth the slower page views and the extra bandwidth costs?“
And what’s the benefit of all those cookies for static resource requests like CSS, JS, or images? Probably none. In a few rare cases, some server configurations actually require session headers to authorize access to some static resources (or to keep a previous client session alive). But this is not a common occurrence on the broad web, and yet cookies are just being wastefully sent along in hundreds of millions of static resource requests every second, all across the internet. Think how much extra bandwidth clogging is happening just from completely ignored and useless cookie transmissions, just in the time you took to read this sentence.
There’s a common myth that if you simply set up a sub-domain (like images.getify.com) and make requests for static resources through that sub-domain, that all those cookies won’t get sent. This is unfortunately pretty much untrue. The reason is, most cookies are set as “global”, meaning they are set on the root domain (getify.com). The browser will send all cookies for every level of the domain being requested against, meaning for blog.getify.com, cookies on both getify.com and blog.getify.com will get sent.
So, just using images.getify.com won’t help much if anything, for exactly the same reason: the browser will still send all those global cookies (like from Google Analytics), which is the bulk of the weight of the cookies that are most concerning performance-wise!
Any Hope?
There’s only one practical solution you can currently do to trim down on these wasted cookies in static resource requests (assuming you in fact don’t need them): use a different domain entirely (not just a sub-domain).
For instance, imagine I were to purchase “mystaticgetify.com”, and were to set that up as an alias to point to my same getify.com site. A request to http://getify.com/images/logo.png (which would have all those cookies added to it) could instead be made to http://mystaticgetify.com/images/logo.png. And magically, all those cookies would not be added to the request!
Many people don’t necessarily have the resources to purchase a second domain name for every single site they own/run. So, another (free) option is a service I have created (currently in private beta, but probably launching publicly soon) called http://2static.it. 2static.it allows you to create free subdomains (like foobar.2static.it) that my DNS servers will just point back at the same IP location as your existing site.
Then, you can set up “foobar.2static.it” as an alias for your page, and start requesting resources like http://foobar.2static.it/images/logo.png. Because “2static.it” is a different base-domain than whatever your site’s domain is, you’ll similarly get the performance-desirable “no cookie sending” behavior for all those requests.
Yes, your users will pay a small penalty for the extra DNS lookup (only the first time, then cached), but if you’re loading a lot of static resources and have lots of cookies weighing them down, you should see a net-positive benefit pretty quickly. Across the sites I’ve implemented 2static.it aliases on, I see on average a 4-6% increase in page-load speed. Others have seen similar (if not better) improvements. Not an earth-shattering metric, but a relevant piece of your overall performance optimization strategy nonetheless.
Another option that’s recently been discussed in the W3C HTML Working Group is the idea of having a “rel” attribute value that could be added to <link>, <script> and <img> tags, something like rel="anonymous", that would instruct the browser not to pass along unnecessary/wasteful headers (like cookies, Referer, etc) on that resource request.
There are some possible issues with this idea, but I think it has some strong potential to greatly improve web performance in this area without all the hoops we currently go through domain-name wise. I encourage all readers to join that discussion and voice your opinions.
Response Headers
So far we’ve been looking at the headers that are sent in the request. Now let’s look at the other side of the transaction: the response headers.
We’ll take a look at a few of these response headers, and ways we might tune them for performance in resource responses. First, though, compare this above response header list to the same page when loaded from a primed cache:

First, let’s take a look at the “Server” header, which is sent in the first response but not in the follow-up (304 Not Modified) response. In this example, the value is “Apache/2”. This is pretty short, all things considered. The “Server” header is basically like the server’s “User-Agent” field. By default, in Apache, it’s much longer, 150 bytes or more, and exposes all kinds of information like which modules are installed (and their versions), etc. Not only is that a potential security risk, there’s almost no reasoning to be made for why the browser needs all that information. Lots of waste.
Apache doesn’t let you remove this header entirely, but you can minimize its value as shown. I would argue that the header is entirely unnecessary and you should be able to completely remove it. Apache, however, has been repeatedly asked over the years why they don’t allow its removal, and have persistently refused to accommodate. Some people have found that if you use a proxy in front of Apache, you can strip out this (and other unnecessary) headers. So, if the 17-19 bytes are something you’re concerned about (especially if you have really high traffic and that waste adds up), that’s a possible approach. Or, you can patch Apache manually and remove it.
Next, the “P3P” header. “P3P” (Platform for Privacy Preferences Project) means a declaration of the server’s privacy policy, and especially related to cookies (specifically third-party cookies). While you may argue there’s some semantic or ethical value to this response header, since this site we’re looking at sends no cookies (no “Set-Cookie” header in either list), the functional value for it is pretty much zero. This is an example of a header that could be suppressed under most circumstances with very little impact to the site’s functionality, except for improved performance!
The “Date” header is an interesting one. Again, it’s semantic value is probably higher than its functional value. The spec states that it is required unless the response “Status” code is 1xx, 5xx (server error), or if the server can’t reliably determine via its own clock what the timestamp of the response is. Presumably, the need for this value is in case the client system has an out-of-sync/incorrect clock setting, the expiration date values can be relative to the proper response “Date” value rather than the incorrect client timestamp.
However, notice that in the case of the 304 response, the “Date” header is not sent by Apache. And that’s from the W3C server hosting the official spec for the HTTP headers! That appears to be a willful violation of the spec by the W3C itself. In any case, I’d argue that perhaps the “Date” header isn’t all that important on the modern web. Admittedly, that’s a minor and probably controversial perspective, but it’s yet another header with dubious usefulness, and thus a little fat that might be trimmed.
“Accept-Ranges” is a sometimes useful header, but in this example, it’s probably not necessary or helpful. Even if the client doesn’t receive this header, it may or may not (even by spec) request byte ranges (for chunked responses, etc). So again, this response header isn’t necessary for that interchange. I say: remove it, save the space.
Expiration
Probably the most complicated, historically confusing, and misunderstood response headers are those dealing with the expiration/cacheability of resources. To fully cover this family of response headers (and a few related request headers even) would need an entire long blog post all in itself. But the topic still bears some brief discussion to help explain minimizing them in the context of performance optimization.
Firstly, let’s discuss the “ETag” (aka, “entity tag”) header. This header is intended to be used to assign a unique “fingerprint” to a resource. The server sends it out, and when the browser next requests that same resource (if it’s still in the cache), the browser will send that “ETag” back, so that the server can compare the previous “ETag” to the resource’s current one. The idea is of course a way for the server to decide if it needs to send a new version of the resource back to the browser.
Closely related is the “Last-Modified” response header, which is obviously a timestamp of the time the resource was last modified (or created, if applicable). Again, if the server sends that response header, the browser will store it with the resource in the cache, and upon next request, will send along a “If-Modified-Since” request header back to the server with that timestamp value in it. The server then theoretically can compare the two timestamps, again to decide if a new version of the resource should be sent out.
In either case, if the browser’s copy of a resource is still valid, that’s when the “304 Not Modified” status is returned, which is comparatively a very small response message (to minimize performance impact). The caching and conditional load behavior is often quite desirable, but sometimes more challenging to implement than it should be, which usually leads to doing it wrong.
In theory, “ETag” is supposed to be a little more reliable/robust for the desired “if modified” conditional reload behavior than comparing timestamps. Whether that is true or not, it should be obvious that using both sets of headers is duplicative, and probably wasteful. While some conditions may exist where having both headers in play provides slightly more robust behavior, it’s probably more true that the net-effect of sending both headers back and forth on every request/response cycle is worse than the few occasions where it prevents an unnecessary reload.
Finally, the “Cache-Control” and “Expires” response headers in the example above are supposed to prevent the above “conditional reload” checks from even happening until after a resource has expired (meaning we’re past the expiration timestamp). That’s the theory, anyway. In practice, I usually see the “If-Modified-Since” (and/or “ETag”) checks (and “304” responses) regardless of “Expiration”. YMMV.
Notice above: the document in question hasn’t changed since Sept 2004, but the “Expires”/”Cache-Control” headers are set for a mere 6 hours past the response time. In the absence of some really non-obvious explanation to the contrary, this seems like a crazy short expiration time for a document that hasn’t changed in over 6 years.
Expirations of anything less than 1 week (most people suggest 30 days) are usually suboptimal. Of course, the average age of content in users’ caches is probably far shy of 30 days, so 7-14 days is about the longest practical expiration. But certainly, expiration of 6 hours on such ultra-stable web content is pretty performance ignorant, when you consider lost optimization on repeat page-views.
New Year’s Resolution: Lose (Header) Weight!
Let me try to wrap up this long and detailed post in a brief and “optimized” way.
Other than perhaps “Cookie” (which could be bigger by itself than all other headers combined), all the headers I talked about here individually are not slowing down your requests/responses by much. But because most or all of them are present in all your request/response transactions, those wastes add up… quickly.
Consider this challenge: spend a few hours looking at your site’s request and response headers, tuning them according to the above discussion, and see if you can’t see a few % improvement in your benchmarked page load speeds (note: always keep regular benchmarks of your performance so you know if what you’re doing is helping or hurting or doing nothing at all!). I’m willing to bet you’ll see the improvement, and be glad you spent the time. Without too much effort, your site will start looking a lot trimmer in the mirror, and your users and your hosting budget will thank you alike.