

Why we need another version of HTTP protocol?
HTTP has been in use by the World-Wide Web global information initiative since 1990. However, it is December 2014 and we don’t have anymore simple pages with cross linked HTML documents as it used to be. Instead, we have Web applications, some of them very heavy and requiring a lot of resources. And unfortunately, the version of the HTTP protocol currently used – 1.1, has issues.
HTTP is actually very simple – browser sends request the server, server provides the response and that is it. Very simple, but if you check the chart below you’ll see that there is not only one request and one response, but multiple requests and responses – about 80 – 100 and 1.8MB of data:
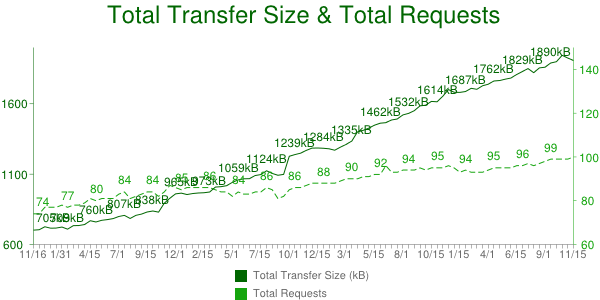
Data provided by HTTP Archive.
Now, imagine we have a server in Los Angeles and our client is in Berlin, Germany. All those 80-100 requests should travel from Berlin to L.A. and then get back. That is not fast – for example, the roundtrip time between London and New York is about 56 ms. From Berlin to Los Angeles it is even more. And as we know, first page load is latency bound; latency is the constraining factor for today’s applications.
In order to speed up downloading the needed resources, browsers currently open multiple connections to the server (typically 6 per domain). However, opening a connection is expensive – there is domain name resolution, socket connect, more roundtrips if TLS should be established and so on. From browser point of view, this also means more consumed memory, connections management, using heuristics when to open a new connection and when to reuse existing one and so on.
Web engineers also tried to make sites loading as fast as possible. They invented many different workarounds (aka “optimizations”) like: image sprites, domain sharding, resource inlining, concatenating files, combo services and so on. Inventing more and more tricks may work to some point but what if we were able to fix the issues on the protocol level and avoid these workarounds?
HTTP/2 in a nutshell
HTTP/2 is binary protocol, where browser and server exchange frames. Each frame belongs to a stream via identifier. The key point is that these streams are multiplexed, they have priorities, priorities are specified by the client (browser) and they can be changed runtime. A stream can depend on another stream.
In contrary to HTTP 1.1, in HTTP/2 the headers are compressed. A special algorithm was invented for that purpose and it is called HPACK.
Server push is a feature of HTTP/2 which deserves special attention. Web Developers actually implemented the same idea for years – the mentioned above inlining of resources in the page is an example of that. Since this is on protocol level, instead of embedding CSS and JavaScript files or images directly on the page, server can explicitly push these resources to the browser in relation with a previously made request.
How does an HTTP/2 connection look like?
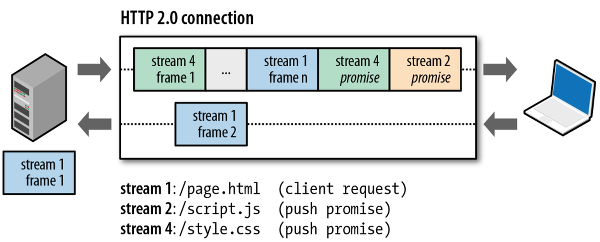
Image by Ilya Grigorik
In this example we have three streams:
- Client initiated request of
page.html - Stream, which carries
script.js– the server initiated this stream, since it knows already what is the content of page.html and thatscript.jswill be requested from the browser as soon as it parses the HTML. - Stream, which carries
style.css– initiated by the server, since this CSS is considered as critical and it will be required from the browser as soon as it parses the HTML file.
HTTP/2 is huge step forward. It is currently on its Draft-16 and the final specification will be ready very soon.
Optimizing the Web stack for HTTP/2 era
Does the above mean that we should discard all optimizations we were doing for years to make our Web applications as fast as possible? Of course not! This just means we have to forget about some of them and start applying others. For example, we still should send as less data as possible from the server to the client, to deal with caching and store files offline. In general, we can split the needed optimizations in two parts:
Optimize the content being served to the browser:
- Minimizing JavaScript, CSS and HTML files
- Removing redundant data from images
- Optimize Critical Path CSS
- Removing the CSS which is not needed on the page using tools like UnCSS before to send the page to the server
- Properly specifying
ETagto the files and setting far future expires headers - Using HTML 5 offline to store already downloaded files and minimize traffic on the next page load
Optimize the server and TCP stack:
- Check your server and be sure the value of TCP’s Initial Congestion Window (initial cwnd) is 10 segments (IW10). If you use GNU/Linux, just upgrade to 3.2+ to get this feature and another important update – Proportional Rate Reduction for TCP
- Disable Slow-Start Restart after idle
- Check and enable if needed Window Scaling
- Consider to use TCP Fast Open (TFO)
(for more information check the wonderful book “High Performance Browser Networking” by Ilya Grigorik)
We may consider to remove the following “optimizations”:
- Joining files – nowadays many companies are striking for continues deployment which makes this challenging – a single line of code change invalidates the whole bundle. Also, it forces browser to wait until the whole file arrives before to start processing it
- Domain sharding – loading resources from different domains in order to avoid browser’s limit of connections per domain (usually 6) is the first “optimization” to be removed. It causes retransmissions and unnecessary latency
- Resource inlining – prevents caching and inflates the document in which they are being stored. Instead, consider to leave CSS, JavaScript and images as external resources
- Image sprites – the problem with cache invalidation is present here too. Apart from that, image sprites force browser to consume more CPU and memory during the process of decoding the the entire sprite
- Using cookie free domains
The new modules API from ES6 and HTTP/2
For years we were splitting our JavaScript code in modules, stored in different files. Since JavaScript did not provide module system prior to version 6, the community invented two different main formats – AMD and CommonJS. Of course, custom formats, like those used by YUI Loader existed too. In ECMAScript 6 however we have a brand new way of creating modules. The API for loading them looks like this:
Declarative syntax:
import {foo, bar} from 'file.js';
Programmatic loader API:
System.import('my_module') .then(my_module => { // ... }) .catch(error => { // ... });
Imagine this module has 10 different dependencies, each of them stored in separate file.
If we don’t change anything on build time, then the browser will request the file, which contains the main module, and then it will make many additional requests in order to download all dependencies.
Since we have HTTP/2 now the browser won’t open multiple connections. However, in order to process the main module, browser still has to wait for all dependencies to be downloaded over the network. This means – download one file, parse it, then oh – it requires another module, download again the required file and so on, until all dependencies are being resolved.
One possible fix of the above issue could be to change this on build time. This means, you may concatenate all modules in one file and then overwrite the originally specified import statements to look for modules in that joined file. However, this has drawbacks and they are the same as if we were joining files for the HTTP 1.1 era.
Another fix, which may be considered is to leverage HTTP/2 push promises. In the example above this means you may try to push the dependencies when the main module is being requested. If the browser already has them then it may abort (reset) the stream by sending RST_STREAM frame.
Patrick Meenan however pointed me to a very interesting issue – on practice browser may not be able to abort the stream quickly enough. By the time the pushed resources hit the client and are validated against the cache, the entire resource will already be in buffers (on the network and in the server) and the whole file will be downloaded anyway. It will work if we can be sure that the resources aren’t in the browser cache, otherwise we will end up sending them anyway. This is an interesting point for further research.
HTTP/2 implementations
You may start playing with HTTP/2 today. There are many server implementations – grab one and start experimenting.
The main browser vendors support HTTP/2 already:
- Internet Explorer supports HTTP/2 from IE 11 on Windows 10 Technical Preview,
- Firefox has enabled HTTP/2 by default in version 34 and
- current version of Chrome supports HTTP/2, but it is not enabled by default. It may be enabled by adding a command line flag
--enable-spdy4when Chrome is being launched or viachrome://flags.
Currently only HTTP/2 over TLS is implemented in all browsers.
Other interesting protocols to keep an eye on
QUIC is a another protocol, started by Google as natural extension of the research on protocols like SPDY and HTTP/2. Here I won’t give many details, it is enough to mention that it has all features of SPDY and HTTP/2, but it is built on top of UDP. The goal is to avoid head-of-line blocking like in SPDY or HTTP/2 and to establish a connection much faster than TCP+TLS is capable to do.
For more information about HTTP/2 and QUIC, please watch my JSConfEU talk.
Thanks to Ilya Grigorik and Caridy Patiño for the review of the article.