

Leon Brocard (@orangeacme) is an orange-loving Senior Solutions Architect at Fastly with many varied contributions to the Perl community. He loves using open source to get things done.
HTTP compression is an important part of the big web performance picture. We’ll cover the history, the current state and the future of web compression.
Lossless data compression makes things smaller
Lossless data compression algorithms exploit statistical redundancy to represent data using fewer bits than the original representation in a reversible way.
Claude Shannon described the process of compression in A Mathematical Theory of Communication in 1948:
The main point at issue is the effect of statistical knowledge about the source in reducing the required capacity of the channel by the use of proper encoding of the information
Lossless data compression algorithms development led to the LZW algorithm (1984), used by the compress application (1985), and then the PKZIP application (1991) with its DEFLATE algorithm which was then used in the gzip format (1992). The zlib library (1995) became a de facto standard compression library for gzip data.
Compression levels balance size and speed
Compression algorithms generally define a file format and how to decompress it. This allows the user to pick an appropriate compression level: either fast compression, which compresses quickly, but doesn’t compress very small or instead best compression, which compresses slowly but generates a smaller output.
With gzip and zlib these levels range from 1 (fast) to 9 (best), with a default of 6.
Fast compression is suited for on-the-fly compression whereas best compression is suited for ahead-of-time compression.
Compression algorithms improve over time. Zopfli (2013) is a much better (but also much slower) DEFLATE compressor. As this targets the gzip file format, this can be used without having to modify any systems. The pigz compressor (2007) assigns Zopfli level 11.
HTTP has supported compression for 24 years
Compression is a core feature of HTTP that improves transfer speed, cache bandwidth utilization and cache utilization.
HTTP/1.1 in 1997 (RFC 2068) added support for gzip, compress and deflate compression as content encodings. gzip compression quickly became the default as it compressed better than compress, which used the patented LZW algorithm, and as Microsoft incorrectly implemented deflate as a broken raw deflate stream instead of the correct deflate stream inside a zlib format wrapper.
Early web content was mostly HTML, CSS and JavaScript served by the same server. Textual content like these compress well with gzip.
Smaller, compressed responses make a huge difference to page load time.
All browsers support gzip compression.
Browsers let servers know which encodings they support by sending a Accept-Encoding: gzip, deflate, br request header (e.g. that is what Chrome sends) and then servers respond with Content-Encoding: gzip and Vary: Accept-Encoding response headers. Upon receiving the compressed body, browsers decompress and then process it.
The HTTP Archive fetches the homepage from each of the top 8 million websites from the Chrome User Experience Report. Most of the homepage requests result in a compressed response:

However, popular object stores such as Amazon S3 and Azure Blob Storage do not support HTTP compression.
Bodies are larger than headers
HTTP responses are made up of headers and a body. Newer versions of HTTP compress headers separately, using HPACK for HTTP/2 and QPACK for HTTP/3. Bodies are generally much larger than headers, so we’ll focus on those.
Modern web makes many requests
According to the HTTP Archive, an average page in 2021 makes ~70 requests, of which:
- ~24 image requests
- ~21 JavaScript requests
- ~7 CSS requests
- ~4 font requests
- ~2 additional HTML requests
Binary content like audio, images, fonts and videos are already compressed and don’t need to be double-compressed. Double-compression would make them slightly larger and take slightly longer to decompress. New audio, image, fonts and video formats improve binary compression over time.
Around a third of requests are binary content.
Modern web uses many third-parties
According to the 2020 Web Almanac, the average page makes ~24 requests to a third-party.
Around a third of requests for a page are sent to other servers.
Modern web still uses some textual content
This means around a third of requests sent to the server for the average page are for textual content that can be compressed.
Browsers have supported the better Brotli compression for 5 years
Brotli is a general-purpose compression algorithm from Google, specified in 2016 with RFC 7932: Brotli Compressed Data Format. It comes with a built-in static dictionary of web-like-strings, which means it compresses web-like-things well, about 10-20% smaller than gzip. Brotli compresses slower than gzip.
Firefox and Chrome supported it in 2016. All major browsers support it, except the deprecated Internet Explorer 11.
Brotli’s static dictionary did not represent the whole web equally and there are some signs that as the web continues to change, the dictionary is ageing and leading to worse compression.
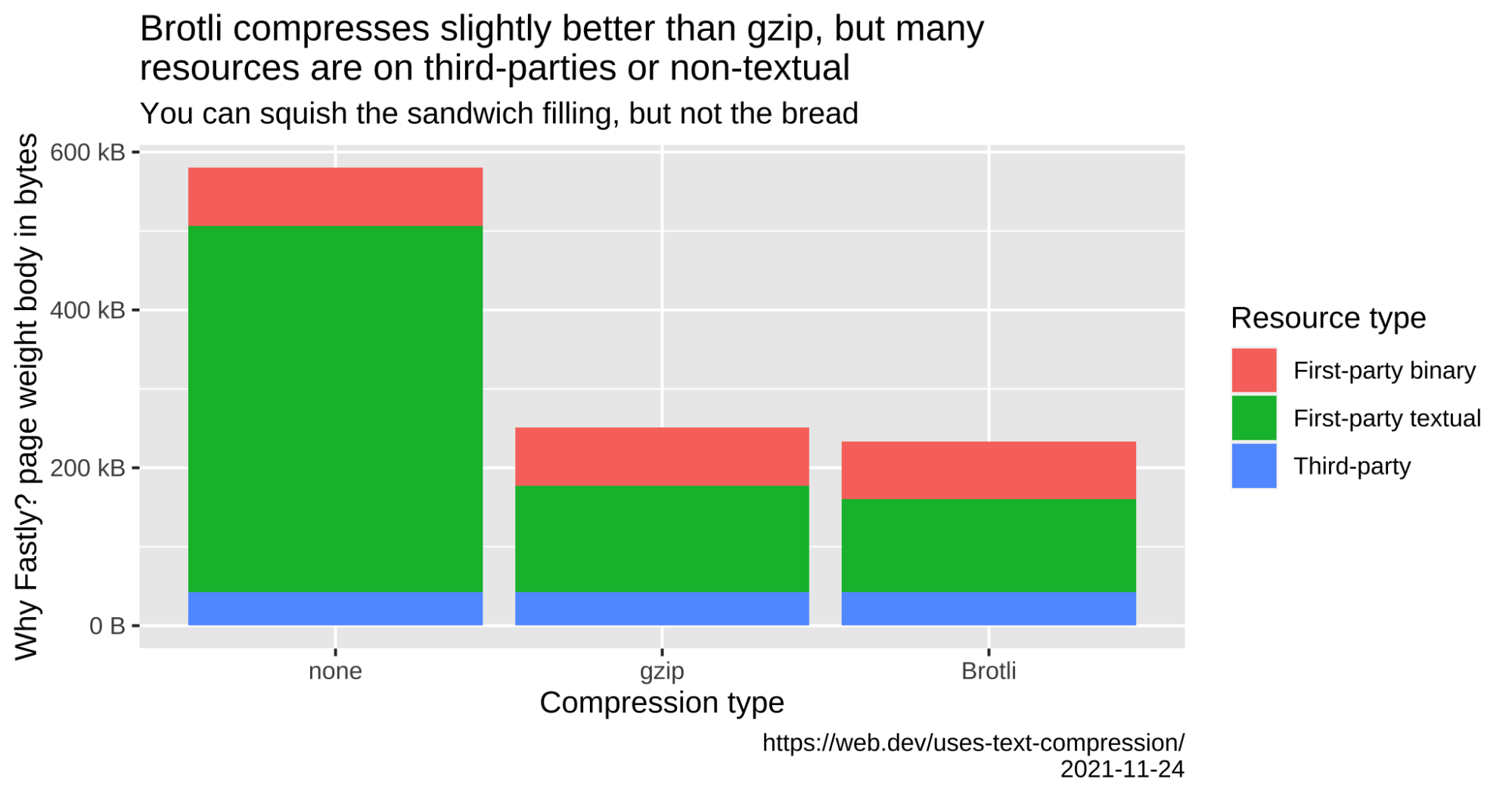
Many resources are on third-parties or non-textual
10-20% better compression than gzip sounds great! However, Brotli doesn’t compress much better when considering the total page weight, as first-party textual content is only a small part of the page:
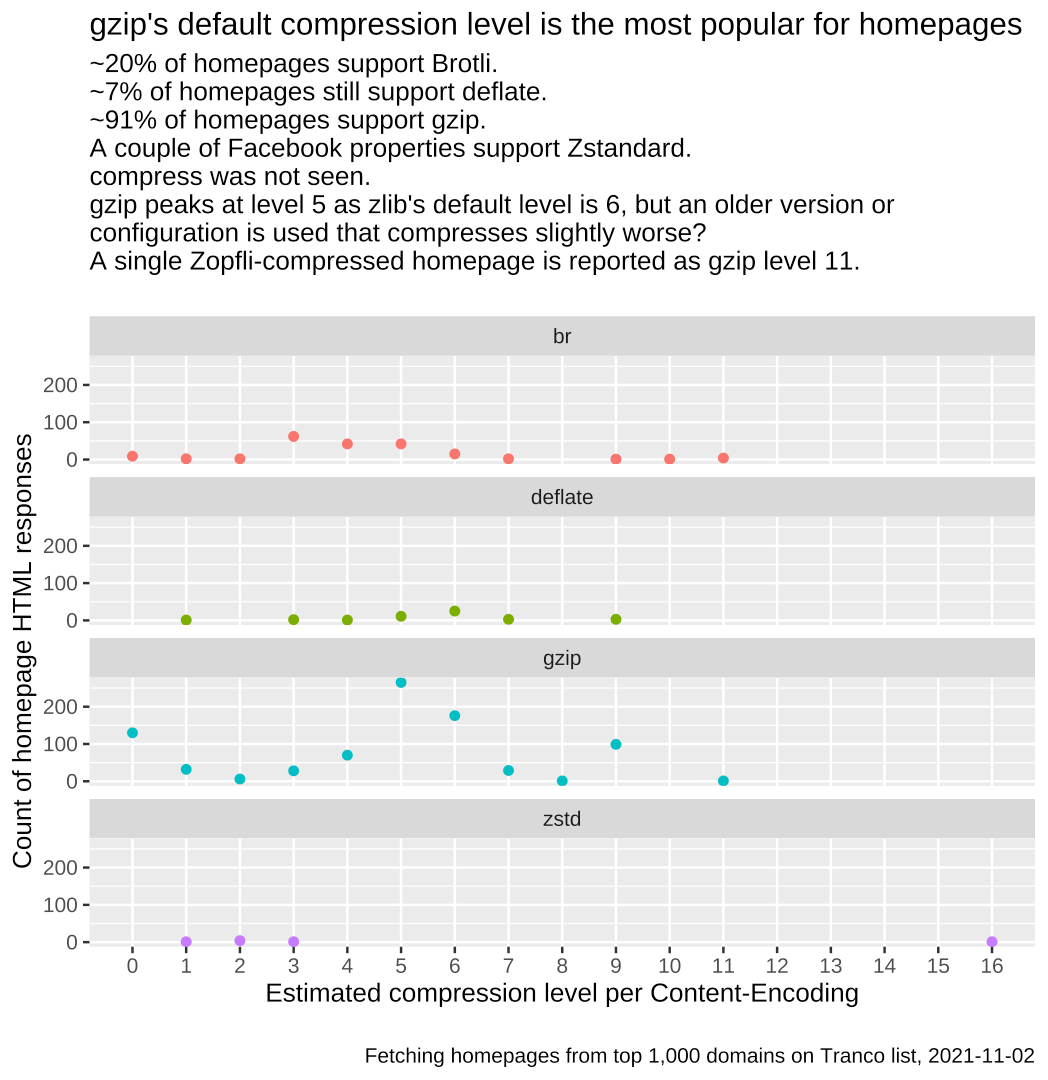
gzip’s default compression level is the most popular for homepages
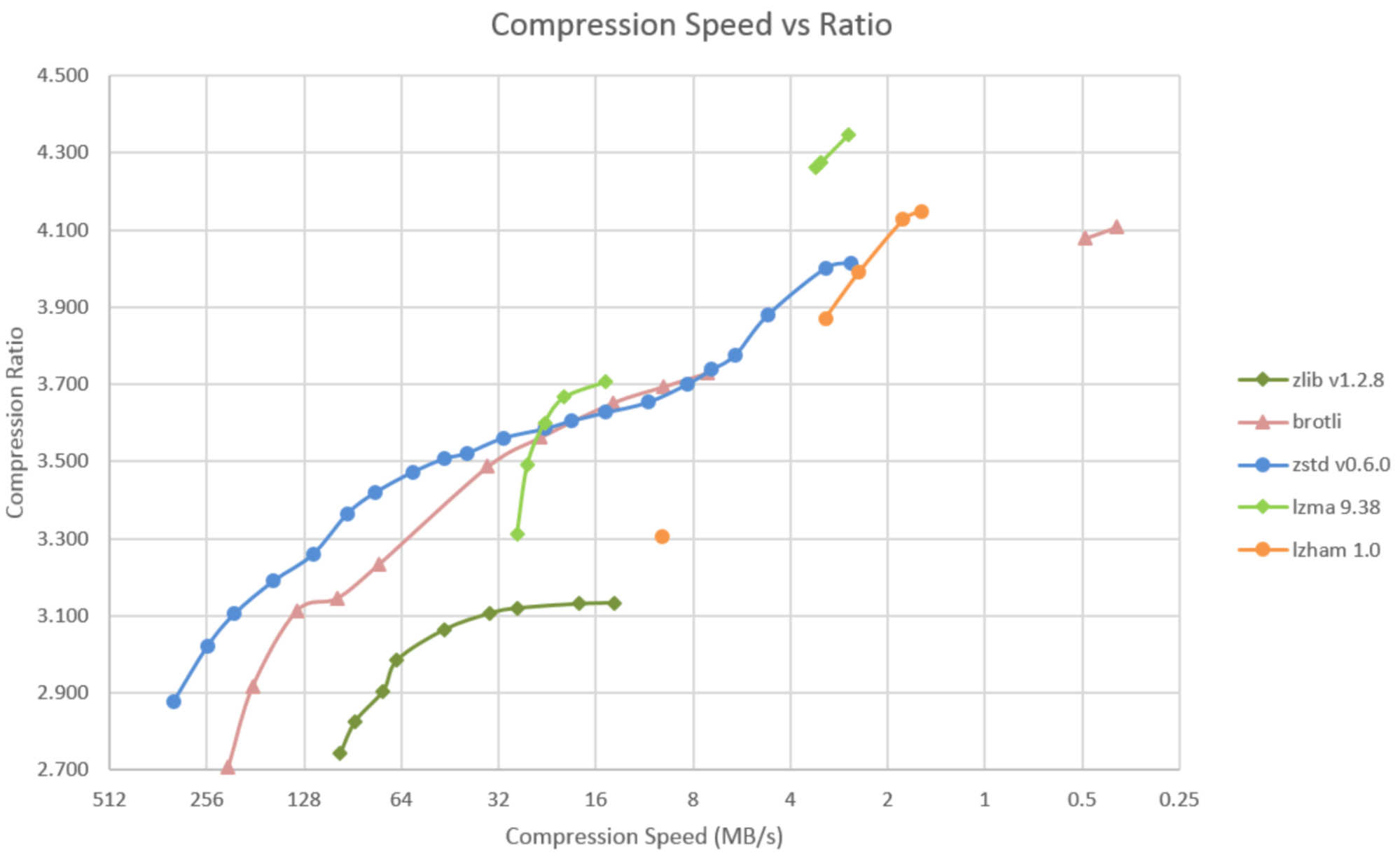
Compression level is a trade-off
The different levels of compression have different compression speeds and compression ratios. The decompression speed does not depend on the compression level.
This (outdated) chart by Facebook is for a large, non-web corpus, but shows how the level for each algorithm changes the compression ratio and compression speed.
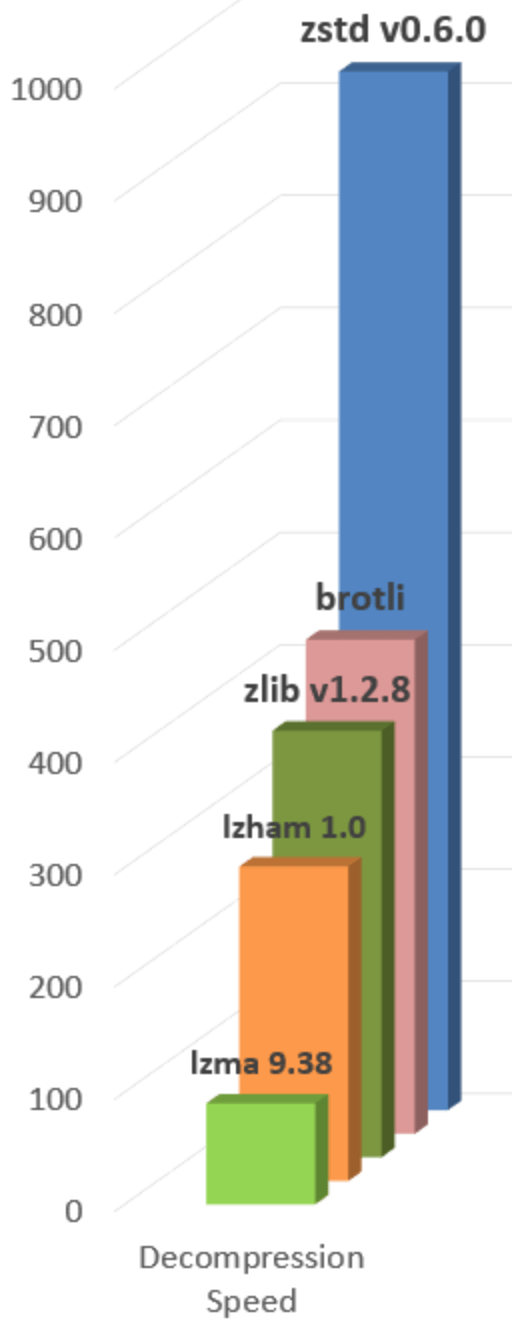
This shows how the decompression speed (in MB/s) varies for each algorithm:
If compressing ahead of time, use the highest level possible. If compressing just in time, use the default compression level.
Zstandard seems promising, but is not supported by browsers yet
Zstandard is a fast compression algorithm, providing high compression ratios. Compared to gzip it’s faster and produces smaller files. Compared to Brotli it’s a little faster and produces similar-sized files.
Zstandard is faster than gzip, compresses better and decompresses faster.
However, browsers don’t seem very interested in adding support, e.g. Firefox: Implement support for Zstandard (zstd) has little progress.
Facebook developed Zstandard, so they support it on their website, but at least for HTML it compares poorly to Brotli:

Zstandard might become more popular in the future (e.g. Zstd Compression in the Browser is a topic at the W3C WebPerf WG @ TPAC 2021 meeting), but at the moment it does not seem to perform well on typical textual web content.
Want to know more?
The HTTP Almanac includes a chapter on Compression.