

Peter Hedenskog (@peterhedenskog.com) works in the Wikimedia Test Platform team at the Wikimedia Foundation. Peter is one of the creators of the Open Source sitespeed.io web performance tools.
Running web performance synthetic testing tools can really be a pain. It’s constant work to make sure to get stable metrics out of your setup so you can find those regressions. You use a bare metal server, you pin the CPU speed, you use a replay proxy to get rid of the noise from the internet and you run many iterations to be able to get stable metrics. Even though you do that, you still get false positives and you need to spend time investigating potential regressions.
Sometime ago I changed most of Wikimedia’s performance regression monitoring to follow a new pattern: analyzing the metrics to make sure a regression is statistically significant and only alert when they are.
Before I tell you how, let me talk about our setup and how we used to run the monitoring.
The setup
We use dedicated servers with pinned CPU speeds running tests against WebPageReplay, a proxy that eliminates network variability by replaying stored Wikipedia pages. Performance metrics are collected and visualized with Graphite and Grafana to monitor changes.
For years, we’ve relied on analyzing the median of the metrics we collect to detect regressions. One key metric is First Visual Change, which measures when something is first painted on the screen for a user. For example, if we test the same page eleven times, we use the median of those eleven runs.
But how can we make sure a regression isn’t specific to a single page? One common approach has been to test at least three different pages and use the median for each. If all three pages show an increase in the median metric, we trigger an alert. A single page might fluctuate due to content changes, but if multiple pages change, it’s more likely due to an underlying issue.
Detecting a regression
We’ve experimented with various methods to detect metric changes:
- Comparing with past data: For instance, comparing current values with the values from one week prior. That will work except if we have an regression one week back in time,
- Setting hard limits: Triggering an alert if a metric exceeds a predefined threshold (e.g. “alert if above X”). This can be ok but it means that you probably often need to tune the X for each URL when your page changes.
Both approaches worked ok but sometimes produced false alerts. By false alerts, I mean cases where an alert fires, we investigate, and ultimately find no real regression.
Another common approach is to visually inspect the metric graph. Can you spot the regression here?
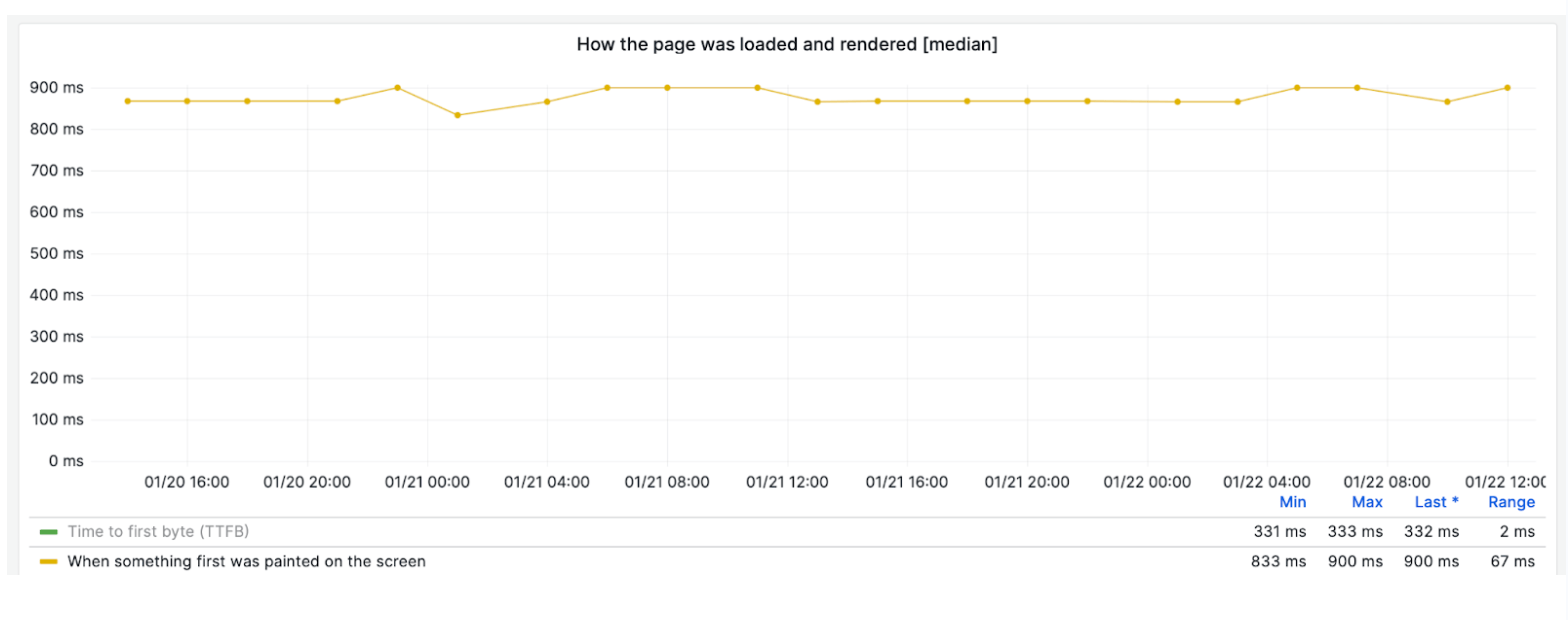
The challenge is that metrics often fluctuate slightly up and down. How can we determine whether these fluctuations represent a genuine regression in our code or just natural variance? One strategy we used was to try to increase the number of runs to stabilise the median and reduce variability.
Using a baseline and Wilcoxon/Mann Whitney U
After talking with Gregory Mierzwinski at Mozilla I decided to try out Wilcoxon/Mann Whitney U statistical tests that will help us understand if a change is statistically significant. What is “statistically significant”? That means that the results or changes that we see in our data are unlikely to have occurred by random chance alone. We will know if the differences are meaningful and not just due to random fluctuations.
Why Wilcoxon/Mann-Whitney U? That test doesn’t assume your data follows the normal distribution. The metrics we collect in web performance, often have more skewness and sometimes have outliers that are far from the rest of the values. The Wilcoxon/Mann-Whitney U test is great here because it can handle these types of data well.
We have a statistical test method but what would we actually use as a baseline? When I first tried it out I used the last run as a baseline, meaning we always compare against the last time we ran the test.
The problem with that is that if we have a regression, we will only see that one time, because the next time the baseline is the one with the regression.
The other way I tried is to do Baseline Sundays (™). That means that every Sunday we create a new baseline and then we compare against that baseline the full next week.
That’s good because there are very little code changes going out on Sundays! Taking that as the baseline for the coming week, we have something robust to compare with. Then the coming Sunday, we take a new baseline and so on.
One potential problem here is that if we have multiple regressions throughout a week, we would potentially only see the first one because then the alerts have fired. We can manually re-baseline if we feel that it’s a problem (I haven’t needed to do that yet though).
How small changes do you want to find?
The Wilcoxon/Mann Whitney U helps us find regressions but there’s one thing missing, should we act on all regressions we find? Well maybe, but how do we quantify a regression? I’ve started to use Cliff’s Delta that measures the effect size. Cliff’s Delta shows how big or small the difference is between two groups. That helps quantify the regression in small/medium or large. A small effect might not be noticeable by most users, medium could be noticeable for users with slower devices/connection. The large effect is a clearly observable regression for many users.
We can then use that in our alerts, so for example we can fire an alert if we have statistical significant change and the change is large. We can then have different severities of our alerts.
Example of what could have been a false positive
Let’s look at an interesting example that would usually have fired an alert because it’s a false positive. Here we will analyse data for a first visual change where the median change is 67 ms (8,3%). At first look, this might seem like a significant regression. However, by applying the Mann-Whitney U test to compare the current metrics against the baseline, we see that the change is not statistically significant.

If we then take a deeper look and look at the individual runs, it looks like this.
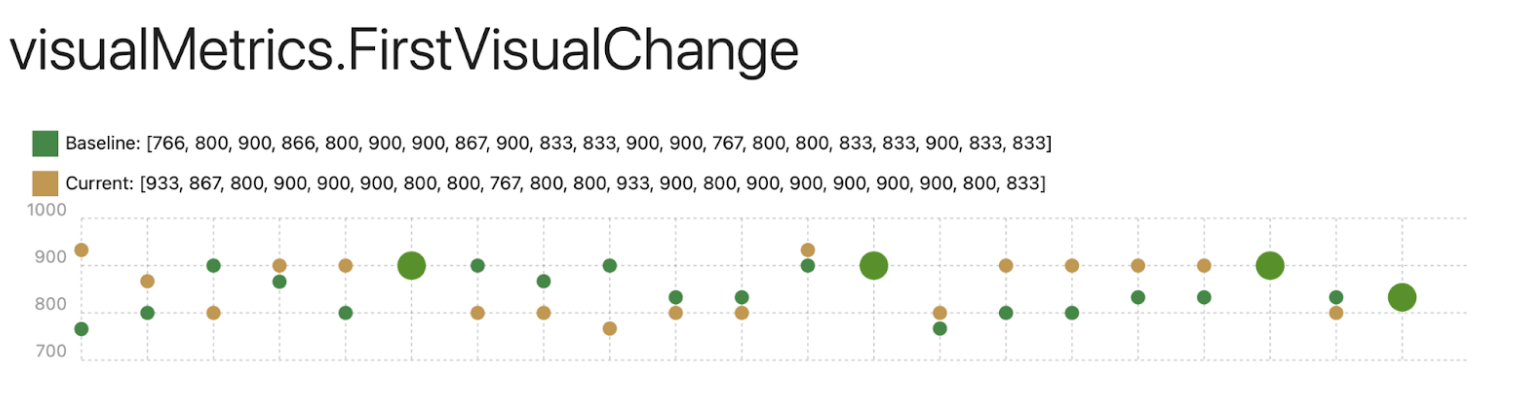
Green dots means the baseline metric, yellow the current test run and large green dots means the numbers are identical.
From the visualization, we can see that the current test runs are sometimes faster and sometimes slower than the baseline. This variability shows how relying on the median alone can mislead us into interpreting variance as a regression. By using statistical analysis, we avoid unnecessary alerts and focus only on meaningful changes.
Summary
You can always tweak performance monitoring and do it a little bit better 🙂 By using statistical tools like the Wilcoxon or Mann-Whitney U test and combining them with effect size measurements like Cliff’s Delta, we’ve changed how we identify regressions. The new workflow is like this:
- Collect data using a stable setup (bare metal, CPU pinned, WebPageReplay).
- Pick a baseline period (e.g., Sunday).
- Collect new data over the week.
- Run Wilcoxon or Mann-Whitney U to test for statistical significance.
- If significant, calculate Cliff’s Delta to see how large the effect is.
- Trigger alerts only if both significance and a certain effect size threshold are met.
The new setup has reduced false alerts and ensures we focus only on meaningful changes that truly impact user experience. This makes our performance monitoring more efficient and more reliable. If you also want to try it out, you can implement it yourself in your tooling or run the compare plugin in sitespeed.io.