

Matt Zeunert (in/mattzeunert) is the founder of DebugBear, a web performance monitoring tool.
Most HTML documents are relatively small, providing a starting point for other resources on the page to load.
But why do some websites load several megabytes of HTML code? Usually it’s not that there’s a lot of content on the page, but rather that other types of resources are embedded within the document.
In this article, we’ll look at examples of large HTML documents around the web and peek into the code to see what’s making them so big.
HTML on the web is full of surprises. In the process of writing this article I rebuilt most of the DebugBear HTML Size Analyzer. If your HTML contains scripts that contain JSON that contains HTML that contains CSS that contains images – that’s supported now!
Embedded images
Base64 encoding is a way to turn images into text, so that they can be embedded in a text file like HTML or CSS. Embedding images directly in the HTML has a big advantage: the browser no longer needs to make a separate request to display the image.
However, for large files it’s likely to cause problems. For example, the image can no longer be cached independently, and the image will be prioritized in the same way as the document content, while usually it’s ok for images to load later.
Here’s an example of PNG files that are embedded in HTML using data URLs.
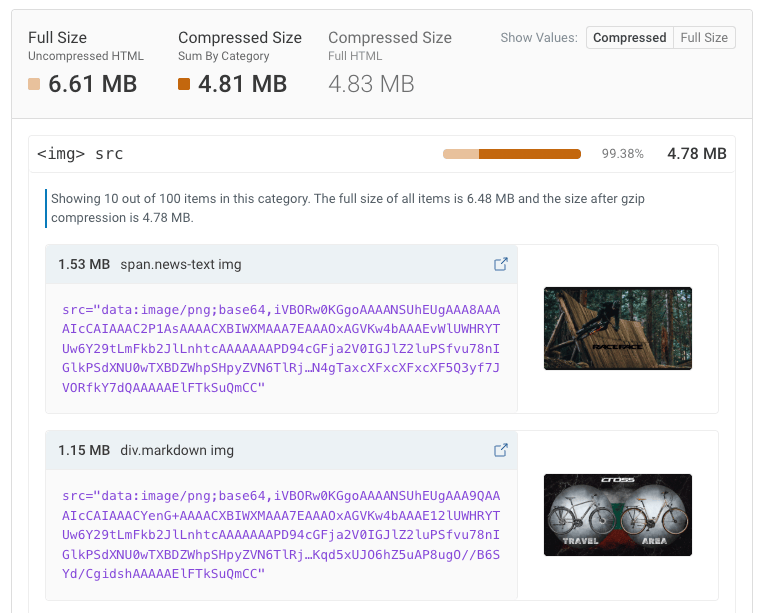
There are different variations of this pattern:
- Sometimes it’s a single multi-megabyte image that was included accidentally, other times there are hundreds of small icons that added up over time
- I saw a site using responsive images together with data URLs. One goal of responsive images is only loading images at the minimum necessary resolution, but embedding all versions in the HTML has the opposite effect.
- Indirectly embedded images:
- Inline SVGs that are themselves a thin wrapper around PNG or JPEG
- Background images from inlined CSS stylesheets
- Images within JSON data (more on that later 😬)
Here’s an example of a style tag that contains 201 rules with embedded background images.
Inline CSS
Large inline CSS is usually due to images. However, long selectors from deeply nested CSS also contribute to CSS and HTML size.
In the example below, the HTML contains 20 inline style tags with similar content (variations like “header”, “header-mobile” and “header-desktop”). Most selectors are over 200 characters long, and as a result 47% of the overall stylesheet content consists of selectors instead of style declarations.
However, the HTML compresses well due to repetition within the selectors, and the size goes from 20.5 megabytes to only 2.3 megabytes after GZIP compression.
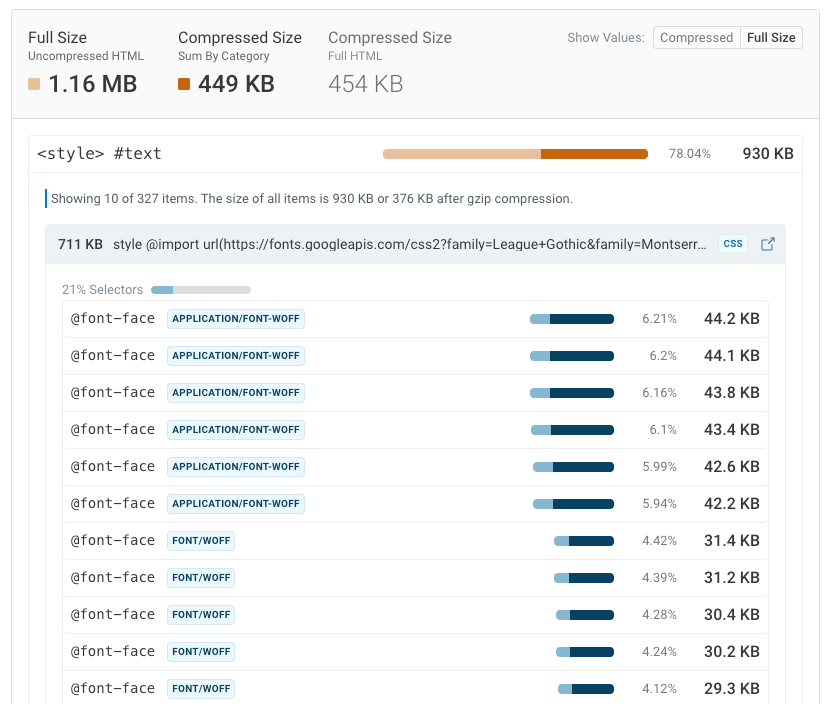
Embedded fonts
Like images, fonts are also sometimes encoded as Base64. For one or two small fonts this can actually work well, as text can render with the proper font right away.
However, when many fonts are embedded, it means visitors have to wait for these fonts to finish downloading before page content can render.
Client-side application state
Many modern websites are built as JavaScript applications. It would be slow to only show content after all JavaScript and required data has loaded, so during the initial page load the HTML is also rendered on the server.
Once the client-side application code has loaded, the static HTML is “hydrated”: the page content is made interactive with JavaScript, and client-side code takes control of future content updates.
Normally client-side code makes fetch requests to API endpoints on the backend to load in required data. But, since the initial client-side render requires the same data as the server-side rendering process, servers embed the hydration state in the final HTML. Then, the client-side hydration can take place right after loading all JavaScript, without making any additional API requests.
As you can guess, this hydration state can be big! You can identify it based on script tags that reference framework-specific keywords like this:
- Next.js:
self.__next_f.pushor__NEXT_DATA__ - Nuxt:
__NUXT_DATA__ - Redux:
__PRELOADED_STATE__ - Apollo:
__APOLLO_STATE__ - Angular:
ng-stateor similar __INITIAL_STATE__or__INITIAL_DATA__in many custom setups
In a local development environment with little data the size of the hydration state might not be noticeable. But as more data is added to the production database, the hydration state also grows. For example, a list of hotels references 3,561 different images (which, thankfully, are not embedded as Base64 😅).
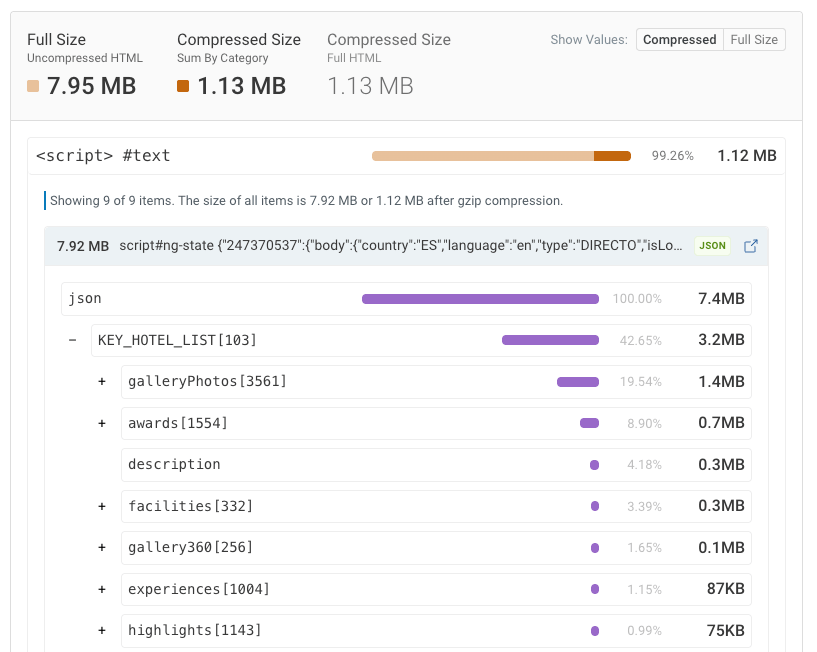
If you pass Base64 images into your front-end components, they will also end up in the hydration state.
This website has 42 images embedded within the JSON data inside of the HTML document. The biggest image has a size of 2.5 megabytes.
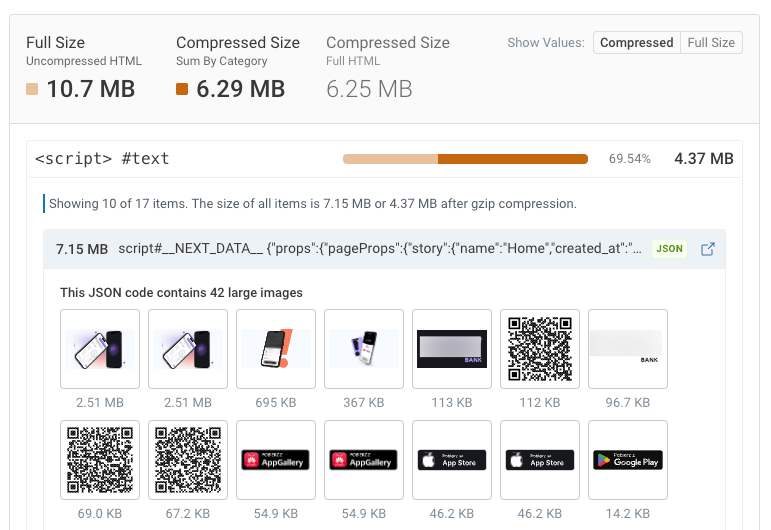
There’s a surprising amount of nesting going. In the previous example we have images in JSON in a script in the HTML.
But we can go deeper than that! Let’s dive into our next example:

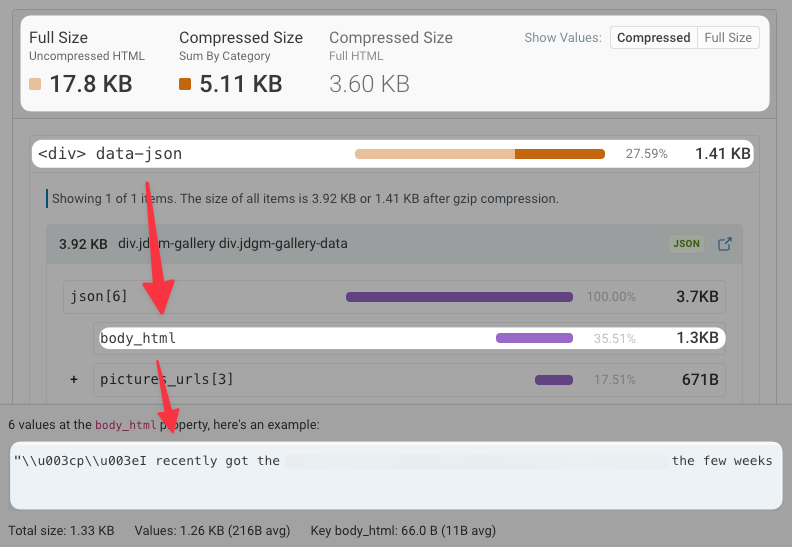
After digging into the hydration state, we find 52 products with a judgmeWidget property. The value of this property is itself an HTML fragment!
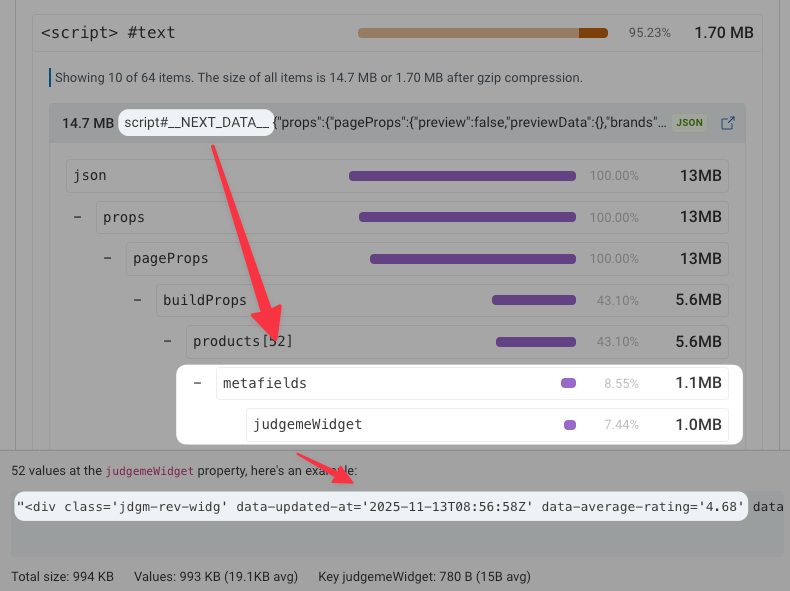
Let’s put one of those values into the HTML Size Analyzer. Once again, most of the HTML is actually embedded JSON code, this time in the form of a data-json attribute on a div!
And what’s the name of the biggest property in that JSON? body_html 😂😂😂
Other causes of large HTML
A few more examples I’ve seen during my research:
- A 4-megabyte inline script
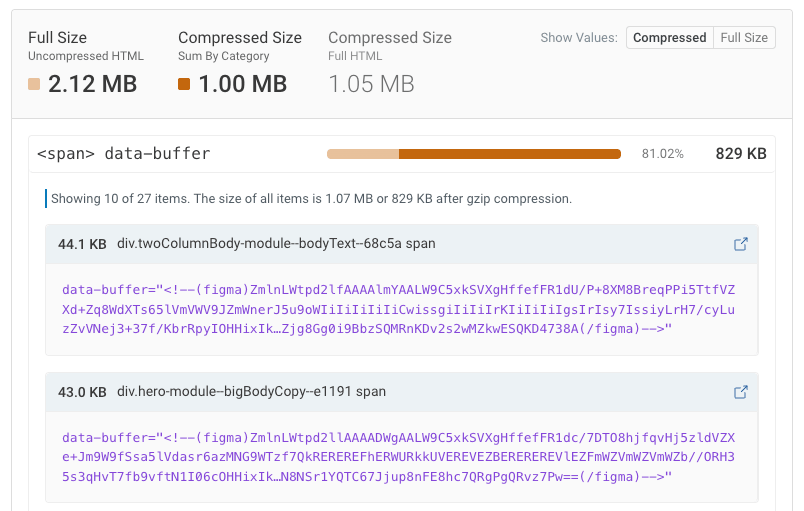
- Unexpected metadata from Figma
- A megamenu with over 7,000 items and 1,300 inline SVGs
- Responsive images with 180 supported sizes
There are still some large websites that still don’t apply GZIP or Brotli compression to their HTML. So while there’s not a lot of code, you still get a large transfer size.
Seeing a 53 kilobyte NREUM script is also always frustrating: many websites embed New Relic’s end user monitoring script directly into the document <head>. If you measure user experience you really want to avoid that performance impact!
How does HTML size impact page speed?
HTML code needs to be downloaded and parsed as part of the page load process. The more time this takes, the longer visitors have to wait for content to show up.
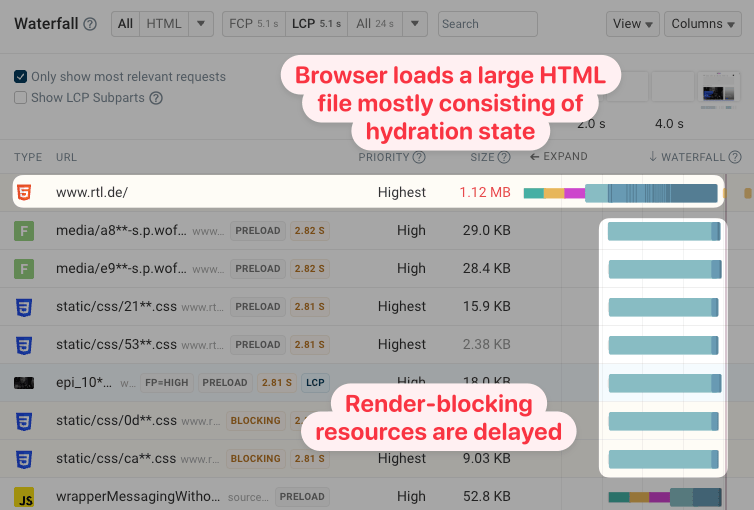
Browsers also assign a high priority to HTML content, assuming all of it is essential page content. That can mean that non-critical hydration state is downloaded before render-blocking stylesheets and JavaScript files are loaded.
You can see an example of that in this request waterfall from the DebugBear website speed test. While the browser knows about the other files early on, all bandwidth is instead consumed by the document.
Embedding images or fonts in the HTML also means that these files can’t be cached and re-used across pages. Instead they need to be redownloaded for every page load on the website.
Is time spent parsing HTML also a concern? On my MacBook it takes about 6 milliseconds to parse one megabyte of HTML code. In contrast, the low-end phone I use for testing takes about 80 milliseconds per megabyte. So for very large documents, CPU processing starts becoming a factor worth thinking about.
Websites with large HTML can still be fast
As you can tell, I might have a bit of an obsession with HTML size. But is it really a problem for many real visitors?
I don’t want to make large HTML files out to be a bigger issue than they really are. Most visitors coming to your website today probably have reasonably fast connections and devices. Other web performance problems tend to be more pressing. (Like actually running the JavaScript application code that’s using the hydration state.)
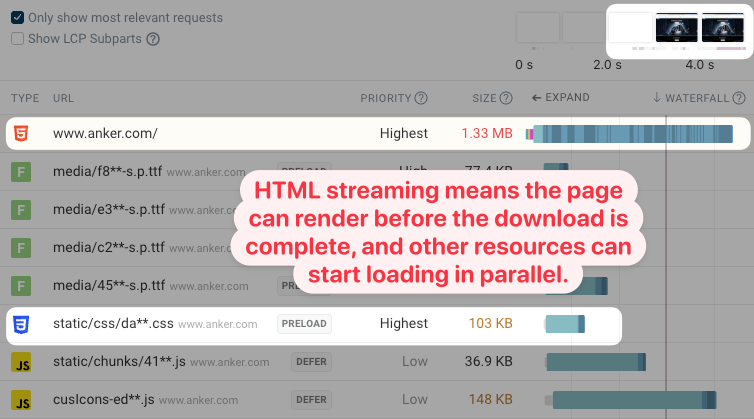
Pages also don’t need to download the full HTML document before they can start rendering. Here you can see that the document and important stylesheets are loaded in parallel. As a result, the main content renders before the document is fully loaded.
The real visitor data from Google’s Chrome User Experience Report (CrUX) shows that this website typically renders under 2 seconds. And that’s on a mobile device!

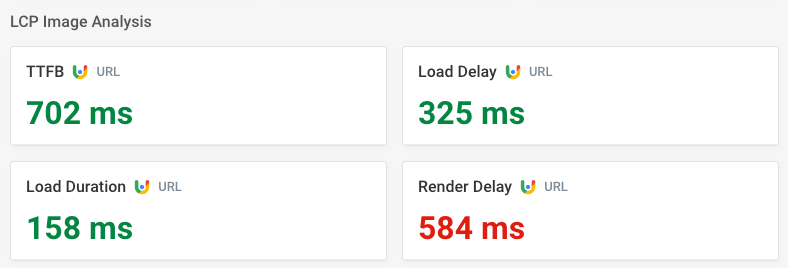
Still, the large document is definitely slowing the page down. One indicator of that is that the Largest Contentful Paint (LCP) image does not show up right away after loading. Instead, CrUX reports 584 milliseconds of render delay.
This tells us that the render-blocking stylesheet, which competes with other resources on the main website server, is loading more slowly than images from a different server.
It’s worth taking a quick look at your website HTML and to check what it actually contains. Often there are quick high-impact fixes you can make.
When images are inlined in HTML or CSS code it’s often intended to be a performance optimization. But a good setup can make it too easy to add more images later on without ever looking at the file being embedded. Consider adding guardrails to your CI build to catch unintended jumps in file size.