

HTTP/2 (h2) is here and it tastes good! One of the most interesting new features is h2 push, which allows the server to send data to the browser without having to wait for the browser to explicitly request it first.
This is useful because normally we need to wait for the browser to parse the .html file and discover the needed links before these resources can be sent. This typically leads to 2 Round-Trip-Times (RTTs) before data arrives at the browser (1 to fetch the .html, then 1 to fetch a resource). So with h2 push, we can eliminate this extra RTT and make our site faster! In this it is conceptually similar to inlining critical CSS/JS in the .html, but should give better cache utilization. Push also helps to ensure better bandwidth utilization at the start of the connection. Plenty of posts talk about the basics, how to use it on different platforms and how to debug it.
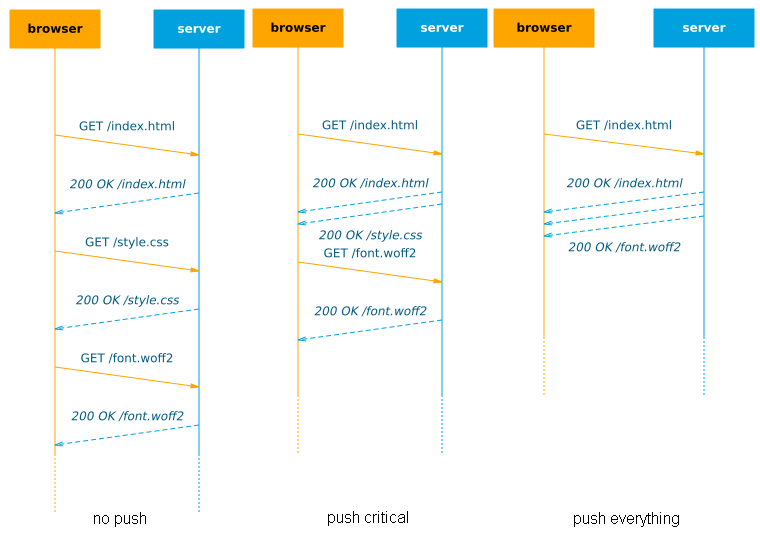
In an ideal world with unlimited bandwidth, we could theoretically just push all our resources with the .html, eliminating waiting for the browser completely (see Figure 1, right side)! Sadly, in practice, even pushing just a tad too much data can actually lead to significant slow downs in site loads.
This post aims to look at some of the low-level issues that determine how useful push can be and how this impacts practical usage. The text should be comprehensible for relative newcomers to the topic, while more advanced readers can find in-depth information in the many reference links and sources and reflect on the ideas in chapter 2.
TL;DR
- h2 Push is not production-ready yet, but excellent for experimentation!
- TCP slow start, resource priorities, buffering and caching conspire on a low level to make h2 push difficult to fine-tune
- Best practices for when to use push vs Resource Hints are unclear
- Automated tooling is probably going to be the preferred way to use push, especially on a CDN level
The utility of push can be diminished if you just do the basics right (e.g. cache .html), but the problem that push solves will always be there. We should be thinking about h2 push as the insurance policy – Colin Bendell
1. Underlying basic principles and limits
The performance of h2 push is heavily dependent on the underlying networking protocols and other aspects of the h2 protocol itself. Here we introduce these principles on a comprehensible level to later discuss them more practically in chapter 2.
1.1 Bandwidth and TCP slow start
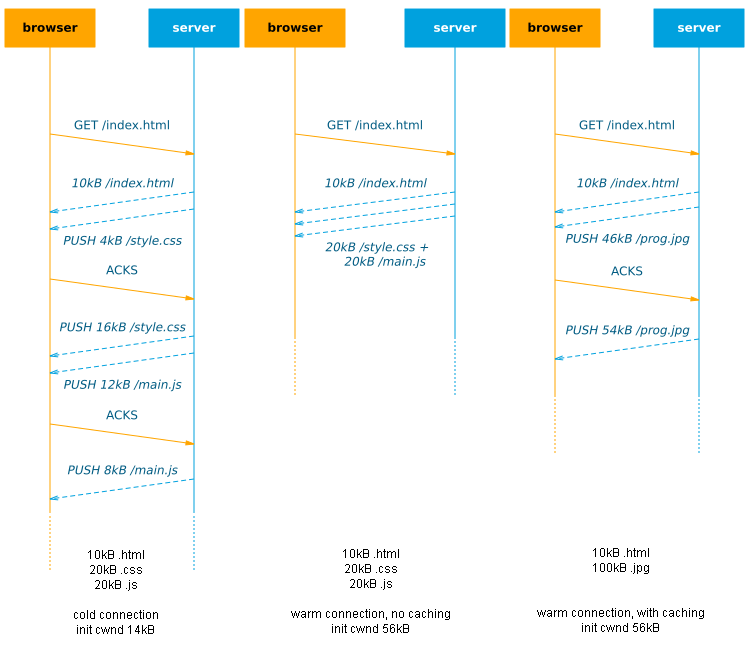
On the internet, every connection has a limited amount of bandwidth. If we try to send too much data at once, the network will start discarding the excess to keep the link from getting flooded/congested (packet loss). For this reason, the reliable TCP protocol uses a mechanism called slow start which basically means we start by sending just a little bit of data at first and only increase our send rate if the network can handle it (no packet loss occurs). In practice, this initial congestion window (cwnd) is about 14kB on most linux servers. Only when the browser confirms it has successfully received those 14kB (by sending ACK message(s)) will the cwnd double in size to 28kB and we can send that much data. After the next AKCs arrive we can grow to 56kB etc.
note: in practice cwnd can grow in other ways too, but the behaviour is similar to the process described above, so we will use the ACK-based model as it’s easy to reason about
{kind=link}
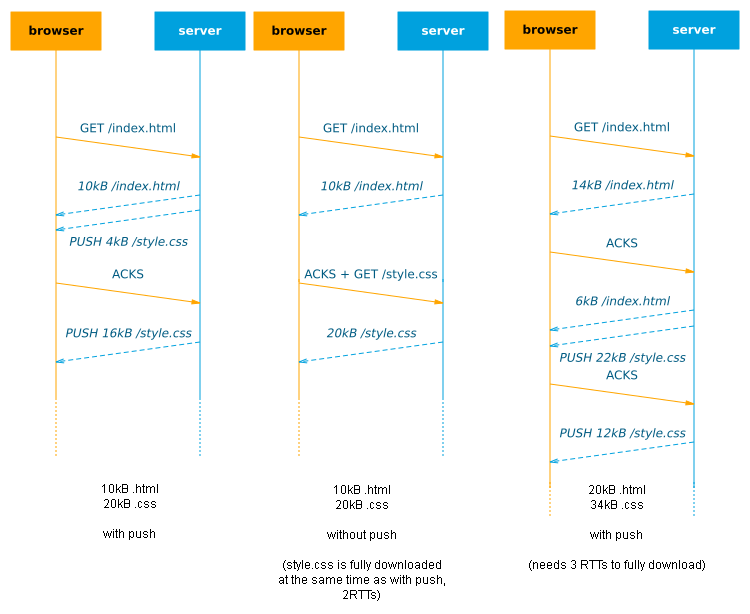
This means that on a cold connection, we can only send 14kB of data to the browser in the first RTT anyway: if we push more, it is buffered at the server until the browser ACKs these first 14kB. In that case, push can have no additional benefits: if the browser just issues a new request along with the ACKs, it would have a similar effect (2 RTTs needed to download the full resource, see figure 2). Of course, on a warm/reused connection, where the cwnd has already grown large, you can push more data in 1 RTT. A more in-depth discussion of this can be found in chapter 1 of this excellent document.
Note that this is primarily a problem because HTTP/2 uses just 1 connection vs 6 parallel connections in most HTTP/1.1 implementations. Interestingly, there are also reports that increasing the initial cwnd doesn’t help much for general HTTP/2, but it’s unclear if this holds true with h2 push as well.
1.2 Priorities
HTTP/2 only uses a single TCP connection on which it multiplexes data from different requests. To decide which data should be sent first if multiple resources are pending transmission, h2 employs priorities. Basically, each resource is given a certain order in which it has to be sent: for example .html is the most important, so it has a priority of 1, .css and .js get 2 and 3, while images get 4.
If we have pending transmissions for multiple resources with the same priority, their data can be interleaved: the server sends a chunk of each in turn, see figure 3. This interleaving can lead to both resources being delayed, as it takes longer for them to fully download. This can work well for progressively streamed/parsed resources, such as progressive jpgs or .html, but possibly less so for resources that need to be fully downloaded to be used (e.g. .css, .js and fonts).

HTTP/2 prioritization is much more complex than these examples, sorting priorities into trees and also allowing interdependencies and weights for subtrees to help decide how bandwidth should be distributed (and how interleaving should be done). Many interesting posts have been written on this.
1.3 Buffers
Networks use a lot of buffering on all levels (routers, cell towers, OS Kernel, etc.) to handle bursts of incoming data which cannot be immediately transmitted. In most cases, once data is in one of these buffers, it’s impossible to get it out or rearrange the data in the buffer. This can make it impossible to correctly apply the HTTP/2 priorities. As a contrived example, if we push 3 large images right after our .html, they can fill up the send buffer. The browser then parses the .html, discovers an important .css file and requests it. The server wants to send this before the rest of the images (because it blocks the page render), but can’t because it is unable to access data in the buffers. Its only choice is to send the .css after some image data, effectively delaying it and the page load, see figure 4.

One possible solution for this is limiting the use of the kernel buffer as much as possible and only give data to the kernel if it can be sent immediately, as explained in detail by Kazuho Oku. This is only partly a solution however, since there can also be significant bufferbloat in the network itself. If the network allows the server to send at a high rate, only to then stall the transmitted data in large internal buffers along the network path, we will see the same detrimental effect. This becomes a greater problem for warm connections, that can have more data in-flight at the same time. This issue is discussed further by google engineers in chapter 2 of this excellent document. Interestingly, they argue that h2 push can also help with this issue, by pushing (only) critical resources in the correct order. This means knowing this exact order is important to get the most out of h2 push (and that pushing images directly after .html is probably a bad idea ;).
1.4 Caching
Modern browsers (and network intermediaries like CDNs) make heavy use of caching to quickly load previously downloaded resources without having to issue a new request to the origin server.
This of course means we don’t want to push already cached resources, as this would waste bandwidth and might delay other resources that aren’t cached yet. The problem is knowing which resources are cached; ideally the browser would send along a summary of its cache when requesting index.html, but this concept is not covered by the official HTTP/2 standard and not implemented in any browser at this moment. Instead, the official method is that the browser can signal the server to cancel a push with a so-called RST_STREAM reply to a PUSH_PROMISE. However, in practice, (some) browsers don’t do this either, and will happily accept pushes for resources they have already cached. Even if they would use RST_STREAM, we can question how effective it would be: much (or all) of the data of the push can already be en-route/buffered before the RST_STREAM arrives at the server, possibly rendering it largely void.
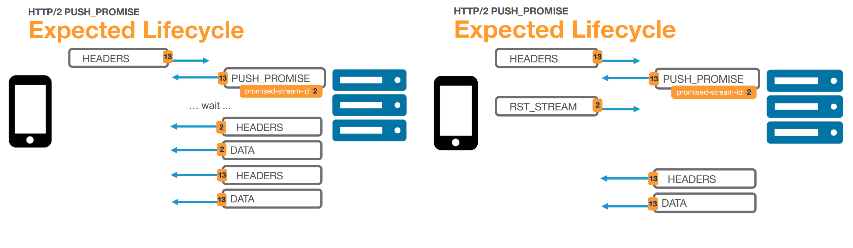
To work around these shortcomings while we wait for an official browser implementation, several options have been proposed, see chapter 3 of this excellent document. The canonical concept is to have the server set a cookie detailing which resources it has pushed and check this cookie for each request to see what push targets remain. This seems to work well in practice, though it can fail if resources are removed from the client’s cache in the meantime.
2. Practical implications
Now that we have a good understanding of the underlying principles at work, we can look at how these affect using h2 push in practice.
2.1 When to push?
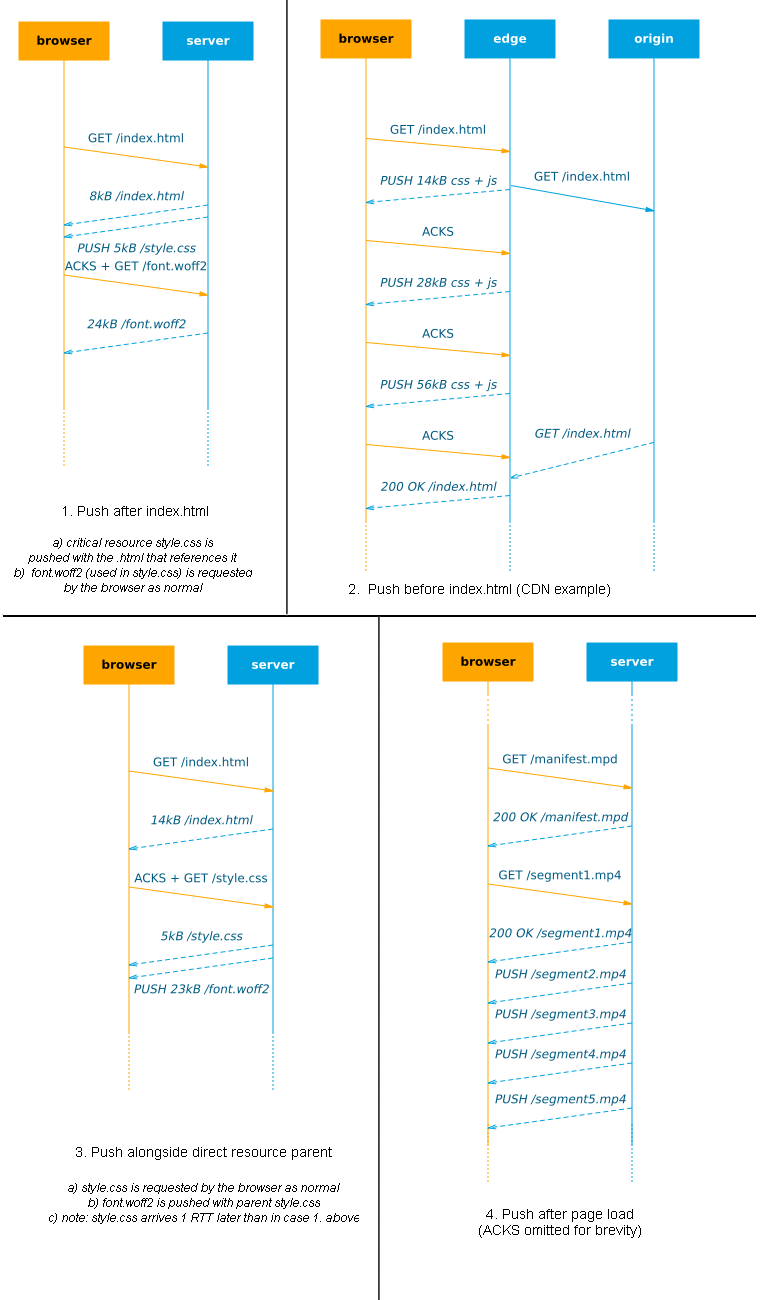
“When to push?” is difficult to answer and depends on your goals. I can see roughly 4 major possibilities (see Figure 6), each with their own downsides :
- After-Html: Directly after index.html (benefit limited to: cwnd – size(index.html))
- Before-Html: Before/while waiting for index.html (can slow down actual .html if wrongly prioritized/buffered)
- With-Resource: Alongside another resource (can be non-optimal but easier to get order/priorities right)
- During-Interactive: After page fully loaded (not for improving key pageload metrics)
Initial page load
It seems that After-Html is what most people think about when talking about push, while it’s arguably the least useful in the list, especially on cold connections (see 1.1). Conversely, Before-Html is a lot more interesting: we can actually increase the congestion window up-front, so that even large .html responses can be sent in a single RTT when they become available. Especially in the case of CDNs/edge servers this can work well if the origin is far away/slow: because of the small RTT between client and edge, the cwnd can grow quite quickly. It is difficult to fine-tune though: if we push too much we might fill up the buffers (1.3) and might not be able to prioritize the .html correctly. Colin Bendell created shouldipush.com to help you assess the gains your site can make if pushing before index.html (before “TTFB: time to first byte”) and after index.html (before “TTFR: time to first resource”)(see Figure 7).
With-Resource could be a little less optimal for faster first load, but this approach might make it (much) easier to manage what to push and limit the risks of delaying other resources (see next in 2.2) as resources are closely tied to other related data. For example in Figure 6, we know style.css will reference font.woff2, so we push it along whenever style.css is requested. This naive scheme means we don’t have to worry about how style.css and font.woff2 fit into the larger “dependency graph“, which makes the setup easier. A lot can go wrong here though and this is probably the least useful option.
After load and across pages
Finally we have During-Interactive, which is often ignored and considered controversial by some because there seems to be a direct, more attractive competitor: “Resource Hints“ (which you may know as <link rel="preload/prefetch">). Using Resource Hints can trigger the browser to fetch a resource before it needs it, both for the current page load and the next. It’s often seen as superior to push because among others it works cross origin, doesn’t suffer from the (current) caching problems and the browser can better decide how to fit it into the download schedule. So after the page is fully loaded and we have some javascript running, we might as well fetch any resource we need via Resource Hints instead of pushing them. It is worth mentioning though that Resource Hints can suffer from the same limitations as push, especially in dealing with h2 priorities and excessive buffering (chapter 5).
Seeing Resource Hints and push as complementary options, I feel there is a lot of room for experimentation here and cases where push can have its place. For example, in academic literature, many papers have investigated push to speed-up video segment delivery. The MPEG-DASH standard streams videos in small segments (e.g. 2s) and instead of waiting for the browser to request the next segment (in time before the playback of the current one finishes), we can use push to instead send available (live) segments immediately. Another interesting paper is MetaPush: the researchers push so-called “meta files” which contain information about resources used in future pages and then use Resource Hints to download them. This should combine the best of both worlds and prevent excessive bandwidth usage.
In the field, Facebook has been using push in their native app to quickly load images/video, as an app has no critical js/css to load first. While Facebook’s image use case looks more like After-Html, push could also be employed in a (Single Page) app context to send along resources with data updates, e.g. when the app fetches the latest content.json which references some images, they can be pushed along.
At Velocity Amsterdam 2016, Amazon’s Cynthia Mai talked about how Amazon aggressively prefetches resources to speed up next-page load, but that <link rel="prefetch"> was too unpredictable and didn’t scale to large amounts of resources (as it seems to only fetch during browser idle time). A smart push scheme could be a more reliable option in this case, as you have more control over what is actually sent. In addition, though I haven’t found many good examples of this, combining push with service workers can be a very powerful concept that can also help with the current caching issues. Finally, I’ve seen it mentioned several times that an origin server might also push updated resources to the CDN edge, which could make for a lower-overhead API between the two.
2.2 What to push?
As discussed in 1.2 and 1.3, push can slow down the initial page load if we push too much or in the wrong order, as data can get stuck in buffers and (re-)prioritization can fail.
To get it right, we need a very detailed overview of the order in which resources are loaded.
Dependency graphs
This load order is related to the “dependency graph”, which specifies resource interdependencies. While this is quite simple in concept (simply build a tree by looking at the child resources each parent resource includes), in practice these graphs can be quite complex (See Figure 8). The very interesting Polaris paper from MIT looks into how you can distill a correct dependency graph and shows that just by loading resources in the correct order/with correct priorities, page load times could be improved by 34% at the median (even without using server push or dedicated browser support!).

Manually creating a correct dependency graph can be difficult, even if we’re just looking at the critical resources. Some basic tools already exist to partly help you with this, popular frameworks like webpack also keep some dependency information and Yoav Weiss is reportedly looking into exposing dependency info via the Resource Timing API (as dependencies and priorities can be different between browsers).
To then use your constructed graph to decide what to push and what to load normally/via Resource Hints is even more difficult. The most extensive work I’ve seen on this comes from Akamai. They use collected Resource Timing data from RUM (Real User Monitoring) to extract the dependency graph and then statistically decide which resources should be pushed. The integration into their CDN means they can also watch out for (large) regressions from push and adapt accordingly. Their approach shows how difficult it can be to properly leverage push and to what lengths you need to go to optimize its operation. Alternatively, CloudFlare discussed pros and cons of other ways a CDN can provide push.
While waiting for advanced supporting tools, we are stuck with mostly the manual methods, and many server/framework implementations primarily look at critical resources at initial page load as the main use-case for push (probably since they are easiest to manually fine-tune), see 2.3. It is here that With-Resource can make it easier (if used conservatively): if we just push direct child dependencies along with a resource, we don’t need to keep the overview of the full dependency graph. This is especially interesting for sites where individual teams work on small feature “pagelets” that combine into a larger site.
Note that these dependency graphs are also needed to optimally profit from Resource Hints!
Warm connections and caching
Getting the push order right is particularly important for cold connections and first page loads (nothing cached). For warm connections or in case many critical resources have already been cached, we suddenly get a lot more options because we can now push non-critical things: do we first push ad-related resources? our hero image or main content image(s)? Do we start pre-loading video segments? social integrations/comments section? I think it depends on the type of site you run and what experience you want to prioritize for your users. I feel that it is in these situations push will really start to shine and can provide significant benefits.
I haven’t seen much material that looks into how push behaves on warm connections/cross pages in practice (except, of course, for this excellent document, chapter 1), which is probably because of the caching issues and the fact that it’s more difficult to test with existing tools. Because of the many possible permutations and trickiness of push, I predict it will be some time before we see this being used properly. Akamai’s RUM-based system also doesn’t include this yet because they are focusing on the other use cases first and, in the cross-page case, because:
The goal is a) predicting the next page correctly b) not burning up a cellular user’s data plan and c) not overcharging our customer for data that an end user doesn’t request (getting the push wrong). This was the failure of the ‘prerender’ Resource Hint. We can do a) really well and can predict the next page with high confidence. But since it’s not 100% guaranteed, the blowback from b) and c) are of great concern. – Colin Bendell
This “wealth of options” becomes even larger if we start prefetching assets for future page loads, as more will be cached and we need to go further and further down the dependency graph for knowing what to push. To make optimal use of this prefetching scheme, we do need to employ some good prediction algorithms. For some sites this will be trivial (Amazon’s product list will probably lead to a detail view somewhere down the line), but other sites might need to use a statistical/machine learning system to predict how users will traverse through their pages. This can of course have deep integrations with the already discussed RUM-controlled push scheme.
Fine-grained pushing/streaming
Up to this moment, we have primarily considered resources as single files which need to be downloaded fully to be used. While this is true for some resource types (.css, .js, fonts) others already allow streaming (.html, progressive images), where the browser starts using/processing the data incrementally/asap. For streamable resources, we might actually use resource interleaving (see 1.2) to our benefit to get some version of the content displayed early on.
For example, the h2o server interrupts sending .html data when requests for .css come in. Akamai did impressively in-depth research on progressive images and the Shimmercat server uses a very nice implementation that allows you to prioritize parts of (progressive) images. And of course, every browser progressively scans incoming .html for new links to request.
If we can figure out how to make .js and .css streamable or make tools to split larger files, we can move towards incredibly fine-grained pushing and get more use out of the low cwnds on cold connections (1.1). Advances in the Streaming API/service workers might mean we don’t even have to wait for browser vendors to start experimenting with this.
2.3 How to push (2016)?
Up until now, we’ve been discussing the problems and opportunities of push without worrying (much) about what is actually possible in the current browser/server implementations.
I don’t think it’s useful to try to give a full overview at this point, since things may look very different a few months from now. Instead I will give a non-exhaustive list of current problems/quirks/gotcha’s to make the point that it might be a little too early to really use push in production.
note: some of these were overheard during conference questions and talks with others, so not everything has a hard reference.
- Priorities are very inconsistent
- HTTP/2 expects the client to specify resource priorities in the requests, while servers are allowed to adhere to them or not.
- Firefox properly creates priority trees according to the spec (dependency-based), while chrome uses only very coarse priorities (weight-based only) and just 1 tree depth (source1, source2, source3)
- Because of this, the h2o server allows bypassing of client priorities to get the expected behaviour (ex. send pushed .css/.js before .html, implying that push should only be used for critical resources).
- Akamai has said it will prioritize .css/.js and adjust the prioritization of fonts in their automated push system.
- The Shimmercat server uses a learning/statistics based method to determine dependency graphs and use them in prioritization.
- Apache allows some fine-grained settings but defaults to a very simple scheme that doesn’t take into account browser differences.
- At this point, there is no way to define custom priorities for the browser to follow (i.e. nothing like
<img src="hero.jpg" priority="2" />) and while this is being discussed, there are no concrete proposals yet. - A deeper discussion can be found in these mailing list threads: thread 1, thread 2.
- Triggering push is inconsistent and too late
- Some frameworks/servers allow direct programmatic access to push via an API (ex. response.push(stream) in nodejs).
- Most servers however are triggered to push when they receive a
Link: <resource.ext>; rel=preload;header from the backend (ex. in PHP). This is exactly the same header as we would use for preload Resource Hints, which makes it a bit confusing for new users, but also creates a nice fallback: if the server doesn’t respect the push “command”, the browser will still preload the resource. You can use thenopushattribute to only get the preload behaviour. - The problem with this setup is that the header can only be sent if the full headers (and HTTP status code) for the “parent” resource are ready. In the case of .html, we need to wait for the .html to be generated and see if it is a 200 or 404 or 500 or … to be able to send along the push headers. This precludes using the Before-Html usecase and defaults to After-Html (Note that this is not a limit of the HTTP/2 protocol, just from using headers to signal push).
- To help with this problem and inter-operation with edge servers (and similar issues with Resource Hints in general), Kazuho Oku proposed the “103 Early Hints” status code, which allows the server to send headers before the final headers are known.
- Browsers disagree on the spec/don’t fully implement it
- Not all browsers have full implementations of H2 push yet (or even HTTP/2 itself for that matter). For example, not all of them agree which resources/responses can be pushed and not all of them correctly coalesce connections for “cross-origin” pushes that resolve to the same domain.
- Colin Bendell created the fantastic site canipush.com to help assess how different browsers react.
- Shoutout to Colin: an interface/overview akin to www.caniuse.com would be interesting as well, so I don’t have to open up all browsers on all platforms myself 🙂
- Not all networks are the same
- Different networks have different bandwidth/delay properties, which impacts how fast the TCP cwnd will grow (and some networks even manipulate this growth for traffic shaping). When pushing, these differences should be taken into account and different push schemes might be needed depending on the prevalent network conditions. A list of common network “bandwidth delay products” can be found in this excellent document, end of chapter 1. They can range from 20kB for 2g to 156kB for cable, which can have a large impact on push performance.
- In the same document, the writers suggest that using push on a cold 2g connection will probably have no benefits for example, unless you have a very small .html file:
We expect more relative improvement for faster connections than for slow connections, since faster connections generally have a higher BDP. It is unfortunate that this trend is not reversed.
-
Miscellaneous
-
nginx doesn’t support h2 push yet and doesn’t seem to have plans to change that any time soon.
-
(Some) browsers currently don’t send RST_STREAM messages for pushed resources that are already in cache.
-
Pushed resources are not used automatically. The browser still needs to request the resource for it to be evaluated (and executed).
-
Pushed resources that the browser hasn’t requested yet stay in a sort of separate “unused streams” waiting area for ~5 minutes and are then removed, so aggressive prefetching for next pages can be problematic.
-
PUSH_PROMISE messages need to contain “provisional headers”, wherein the server tries to predict with which headers the browser will request the resource. If the server gets it wrong (e.g. the response depends on cookies) and the provisional headers don’t match the browser-generated request headers, the pushed resource can be ignored by the browser and a second request is made (source1, source2, source3, source4).
-
Lists of resources to push are fundamentally de-coupled from the actual .html sent, so with wrong list-management we can easily push outdated assets (ex. still sending main.js?v=1 instead of main.js?v=2). Currently there are no browser-based APIs to programmatically catch this or to be alerted when a pushed resource remained unused (use chrome://net-internals to find unclaimed pushes). Without proper tooling, the wrong assets could be pushed for a long time before anyone noticing.
-
Using HTTP/2 and push and improving cache-hits by splitting your files into smaller chunks can have unintended side-effects, for example higher overall filesize due to lower compression ratios.
-
Kazuho Oku recommends not using load balancers / TLS terminators in combination with HTTP/2 push since they can introduce extra buffering in the network.
-
Push can use a lot of unnecessary bandwidth when used for non-critical assets (that might not be downloaded anyway). As such, in my opinion developers (and maybe servers) should respect the “Save-Data” header and be much more conservative about what they push if it is set.
-
3. Personal conclusions
After this wall of text, I still have the feeling many (important) details on h2 push remain undiscussed. Especially given that h2 push seems to only grant limited performance gains (especially for cold connections on slow networks) and can sometimes even slow down your site, is it worth all this effort? If Akamai has to use a complex RUM-based data-mining approach to make optimal use of it and nginx doesn’t consider it a priority, are we not doing exactly what Ian Malcolm warned about in Jurassic Park? Shouldn’t we just use Resource Hints and drop push?
{kind=link}

While I would agree HTTP/2 push isn’t ready for production yet (and, in my opinion, the same could be said to a lesser extent for HTTP/2 in general), I feel we’re just getting to know these new technologies and how to best use them. It is said the best laid plans of mice and men fail at the first contact with the enemy, and I feel the same applies for most new standards: even though many people have spent years thinking about them, things start to unravel fast when used in practice and at scale. This doesn’t mean they don’t have merit or potential, just that we need more time to figure out best practices (how long have we been optimizing for HTTP/1.1?).
Many of the biggest current issues (e.g. cache-digest, early hints) will be solved soon and implementations will mature. Other underlying concepts such as dependency graphs, explicit prioritization, user behaviour prediction (for prefetch) and more fine-grained/interleaved streaming are useful for many more techniques than just push and will rise in the years to come. QUIC, the next big protocol™, is heralded to help with the buffering issues, alongside offering many other interesting features. Interesting times lie ahead for webperf and I think h2 push will find its place in the end.
For me personally, I hope to do some research/work on the following items in the months to come:
- How larger initial cwnds can affect push performance
- (Cross page) push performance over warm connections and with cached critical assets
- Using service workers as an orchestration/scheduling layer (+ using Streams API to go fine-grained)
- Completely bypass browser priorities and do full custom multiplexing on the server (~Polaris from the server-side, i.e. by sending up-front PUSH_PROMISE for every known resource)
- The new http2_server_push drupal module (in cooperation with the great Wim Leers)
I hope you’ve learned something from this post (I certainly have from the research!) and that you will start/continue to experiment with HTTP/2 push and join the webperf revolution!
Thanks to Colin Bendell and Maarten Wijnants for their help and feedback. Thanks to all the people who have written and talked about this topic, allowing me to piece together this document.
Custom figures were made with https://mscgen.js.org/, https://draw.io and https://cloudconvert.com/svg-to-png.
Last update: 30/11/2016
Live version: https://rmarx.github.io/h2push-thedetails/