

Two years ago I wrote about Leveraging Browser Storage for a Faster Web. The gist of the technique is to persist AJAX payloads in either localStorage or IndexDB so future network requests can be avoided. The overall mechanism allows you to control data life spans and purge stale data. By avoiding excess network requests the customer enjoys a must faster loading and reacting application. You also avoid excess bandwidth costs for you and your customer, plus your servers are less taxed. Everyone wins.
I adopted this technique many years ago to help with mobile user experiences and as a way to skirt around the limitations of the appCache specification and improve overall performance. By persisting data and application assets in browser storage you gain granular control over content caching. AppCache, while a good start, makes content management hard. appCache does not include advance caching logic. Instead appCache is a rather ‘flat’ specification where you either cache and asset or don’t. appCache offers no control over dynamic assets, nor the ability to purge stale cache.
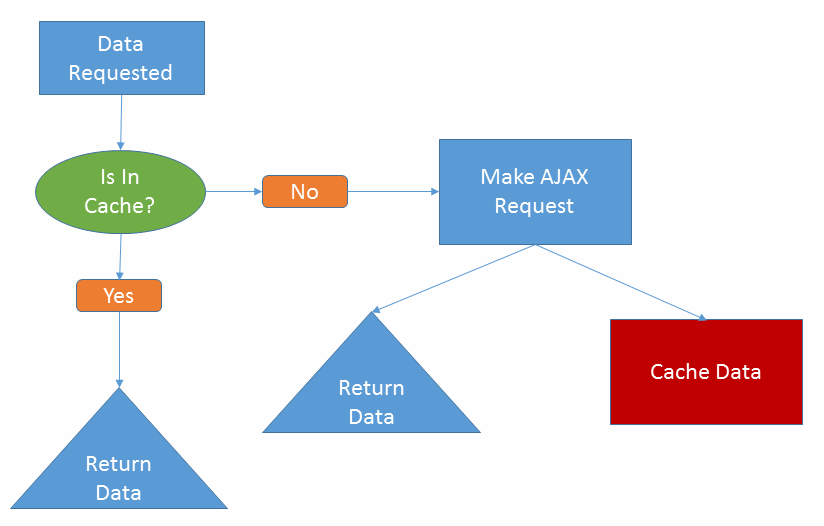
Today we have a new ally when it comes to HTTP request caching and offline capabilities, Service Workers. The web community has known appCache was not a great solution to managing offline applications, Service Workers are a second take to solve an important problem. This time we got the specification right by making the solution extensible, yet manageable. Instead of having a ‘hidden’ cache, developers can access a rich Cache API available within service workers. With some simple feature detection you can use either the browser storage cache solution I described two years ago or the new Service Worker solution.
This is approach applies progressive enhancement concepts, enabling caching for browsers that may not have implemented service workers yet. Over time the legacy caching technique will naturally fade away.
What is a Service Worker?
A Service Worker is a new browser platform API, nearing standards recommendation status. All the browser vendors have either shipped working implementations, are working on implementations or expressed support for the standard. If a customer’s browser does not support Service Workers you can feature detect and fall back to an alternative solution for your problem set.
if ('serviceWorker' in navigator) {
navigator.serviceWorker.register('/sw.js').then(function(registration) {
//do something here
});
} else {
//implement legacy caching logic
}
Service Workers operate on a background thread, freeing the main UI thread from any work load needed by the Service Worker. Because Service Workers operate in the background they can perform many tasks browsers have not been able to offer, like native push notifications. Service Workers are designed to be an extensible API, serving as a ‘spine’ for current and future APIs to be added. Today, service workers feature attraction is a combination of the Fetch and Cache APIs. Together they empower developers to granularly control their application’s network requests.
How Caching Works in a Service Worker
Before diving into the details of service worker caching its worth a quick exploration of the service worker ecosystem. Before a browser can implement service worker it must support the Fetch API. Fetch is a modern replacement for the traditional AJAX mechanism we know and love over the past decade or so. Fetch is more streamlined, based on Promises and designed from scratch to better meet today’s coding and performance expectations.
As Fetch relates to service workers there is a ‘fetch’ event a service worker can subscribe. When a service worker subscribes to a fetch event it can intercept all network requests. Subscribing to the fetch event is done by by adding a callback to the fetch event using the addEventListener function just like you would to regular DOM events.
self.addEventListener('fetch', function (event) {
// intercept fetch request
// (any request from the UI thread for a file or API)
// and return from cache or get from server & cache it
event.respondWith(
caches.match(event.request).then(function (resp) {
return resp || fetchAsset(event);
})
);
});
Examining the example code you no doubt see the self object and are wondering what ‘self’ references. Within a service worker you can access the worker’s context or object using the implied self object. You can think about it in terms of an automatic ‘this’ variable.
The fetch event passes a single object parameter, represented by the event variable. By calling the event object’s respondWith function you can execute a function and its return value is bubbled back through the fetch event handler. In essence you are intercepting a network request and controlling how the browser responds. This is a very powerful action, giving you complete control over any network requests. This includes AJAX or direct file requests, like an image element loading a src image.
Inside the example respondWith function the code exercises the caches match function. Again we see a ‘global’ variable, caches. This is an object that abstracts access to cached content. In this case network requests requests and responses. Notice I did not say files, but request & responses. When a response is cached the entire request transaction object is stored, not just the file or payload. This can later serve a valuable purpose by giving us access to the URL and headers.
In the example above all caches are tested using the matches function. Because the caches match function returns a promise you can return a matching response or pass the request along to retrieve from the server. In the example the code performs a simple coalesce, if the resp object exists, return the cached version. Otherwise fetch the asset from the server.
Before continuing with the caching pipeline, we should explore the Cache API. In the code above caches is referenced. The Cache API allows you to create multiple, named caches. This can be useful if you need to segment cached items. For example images, JSON or API data and other application assets in siloed caches. You have the flexibility to apply different caching and parsing logic to each request type. You are free to cache everything in a single cache, it is completely up to you.
The cache matches function examines all caches to see if there is an object that matches the request object’s pattern, which would be the url. You are not limited to querying all caches at once. You can reference a specific cache by name and call the matches function. This could prove beneficial if your caches persisted larger amounts of data or you have many caches. Your mileage may vary across platforms and devices, which is why you should always test your solutions.
If you need to fetch the asset from the server you need logic in place to cache the response. This being done in the fetchAsset function.
function fetchAsset(event) {
if (event.request) {
return fetch(event.request).then(function (response) {
cacheRequest(productImages, event, response.clone());
return response;
}).catch(function (exc) {
console.error("failed fetching ", event.request.url, " : ", exc);
});
}
}
The function is designed expecting to be called from the fetch event callback, thus the event object is the expected parameter type. The function performs a quick check for the existence of the request object. If satisfied it then performs a fetch call, just as you might have done in your application’s run-time code. When the fetch returns the response is then cached. In this example the cacheRequest function is called, passing a cache name, the event object and a clone of the response object.
I want to point out the need to clone the response. If the response object was directly cached the object would in essence be swallowed by the caching process and could not be returned to the initiator. This would result in an exception or at best a very poor user experience. The response object contains a clone function, taking care of creating a new response object just like the original response object.
Before caching a response you need to open a specific cache. In the example the target cache is based on the name passed to the cacheRequest function. When the cache opens you can then put the response in the cache. In the following example you see you need to supply a key and a value. The key is the request object, while the value is the response.
function cacheRequest(cacheName, event, response) {
caches.open(cacheName)
.then(function (cache) {
cache.put(event.request, response);
})
.catch(function (e) {
console.log("error: ", event.request);
});
}
In the caching technique I described two years ago it assumed localStorage, or at least was designed to work within some limitations due to localStorage. This is where my previous solution is not as robust because localStorage limits keys and values to strings. In order to persist the key as a request object you would need to stringify the object. Which should work in theory, I am sure some problems would reveal themselves. Let’s not visit that possibility since the Cache API a nicer solution today.
At this point the service worker has either retrieved the response from cache or retrieved it from the server and cached the response. Either way the fetch event handler returned the requested response. Your application can now continue on its merry way.
Benefits of a Client Cached Responses
I hope the reality of caching responses in the browser excites everyone because it offers many tangible user experience benefits. As wise people have stated, ‘the fastest request is the one that is never made’. By intercepting all calls to the server and returning local files you are dramatically reducing time to load those files and data in your application. Of course an initial request will always need to be made, this is a necessary evil.
The obvious benefit is the ability for your application to load and respond faster to customers. However another benefit of the service worker and client-side caching is the ability to work offline. Working offline has long been one of the top feature requests consumers and businesses alike. But it is more important then handling true offline situations.

How often are you on your mobile device and see you have connectivity bars, only to be frustrated by a site that either wont open or takes for ever to open? Chances are you encounter this scenario often. You are not alone, your customers do too. We have come to affectionately call this experience Lie-Fi. This is where your device tells you it is connected to a network and possibly the Internet, but in reality it is not connected. The problem lies beyond the scope of this article, but typically resides in the way cellular data networks operate. What is important is service worker caching gives you an opportunity for your application to still function in the absence of any network connectivity.
Of course your application’s personality is an important consideration to the offline experience. Let’s take this year’s most popular application, Pokemon Go. A fun game to play, but how often were you frustrated by a non-responsive experience or had to restart the application due to network issues? If you are like me more than you care to admit. Unfortunately for Niantic, Pokemon Go does require good connectivity to play effectively. However, a service worker gives you a fighting chance to provide a better user experience to the end user. The user wont be able to find freshly spawned Pokemon, since those come from the server.
Having granular control over how assets are retrieved as well as cached gives you an opportunity to log requests locally and possible set request timeouts to shorter or longer periods as needed. So maybe when a customer is experiencing Lie-Fi you can pass along a kind message alerting them to the situation and offer some sort of alternative.