

Peter Hedenskog (@soulislove) works in the performance team at the Wikimedia Foundation. Together with Tobias Lidskog and Jonathan Lee, they are the core team of sitespeed.io.
At the Wikimedia Foundation we’ve been working on finding web performance regressions for a couple of years. We are slowly getting more confident in our metrics and find regressions easier. Today I wanna show you how we automated finding regressions in production using open source tools.
Back in the days – RUM only
When we started out we only used RUM to find regressions. Back then (and now) we used a home made JavaScript to collect the data. We collect metrics from one out of thousand users and pass on the metrics to our servers that later ends up in Graphite. We collect Navigation Timing, a couple of User Timings and first paint for browsers that supports it.
Finding regressions
The way we found regressions was to closely look at the graphs in Graphite/Grafana. Yep watching them real close. The best way for us is to compare current metrics with the metrics we had one week back in time. The traffic and usage pattern for Wikipedia is almost the same if we compare 7 days. Comparing 24 hours back in time can also work, depending on when you look (weekend traffic is different).
Did we find any regressions? Yes we did. This is what one looked like for us (wmf.x is different releases):
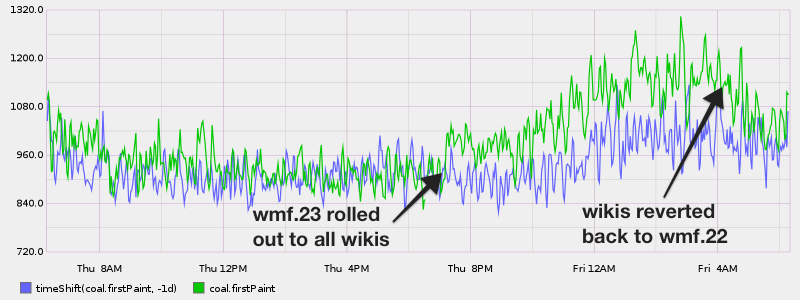
Looks good right, we could actually see that we have a regression on first paint. What is kind of cool is that the human eye is pretty good at spotting differences between two lines.
The problem(s)
We know we could find regressions, but what kind of regressions? They probably need to be large for us to find them since they must affect a large user share for us to see them, we use one big bucket.
We also only focused on browsers supporting first paint so we are in the dark for browsers not supporting first paint. We focused on first paint because most of the other metrics are browser focused instead of user-focused. We look forward to other user-centric metrics like first meaningful paint but it seems it needs some tweaking before it is correct.
And of course it is super tiring to look at the dashboard all the time 🙂
The solution
We needed to collect more user-centric metrics and we need to find a way to automate the alert so we don’t need to watch those graphs all the time.
WebPageTest
We started by setting up a WebPageTest instance (to give us more user-centric metrics like SpeedIndex, first visual and last visual change). We test a couple URLs hourly to make sure the performance is not regressing. We have our setup documented here.
Grafana
We are a heavy Grafana user at the Wikimedia Foundation. Our graphs are open so you can check them out yourself: https://grafana.wikimedia.org/
And in Grafana 4 it finally happened, Grafana supports alerting on dashboards! Alerts in Grafana is pretty cool: You create queries against your metrics and then set a limit on when you want to fire an alert. You get notified via email, Slack, PagerDuty, HipChat and more.
Setup
We have set up alerts both for RUM and synthetic testing. I’ve spent a lot of time tuning and setting up web performance alerts and the best way so far has been to create one set of alert queries that compare the metric in percentage. Talking about a change in percentage is easier for people to understand than the raw change in numbers. And then we have one history graph to the right. It looks like this:
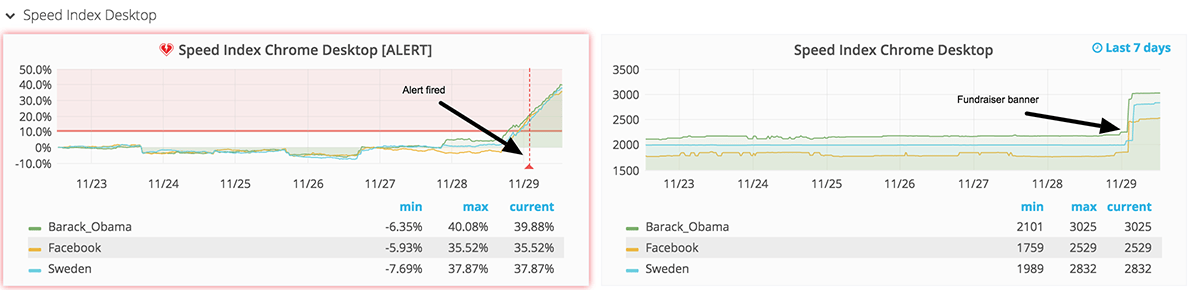
To the left we have changes in percentage. These are the numbers where we add alerts. In this case, we first create a query and take the moving average seven days back (this is the number we will use and compare with) and then we take the moving average of the latest 24 hours. We have a big span here of 24 hours, meaning we don’t find regressions immediately but that helps us to have stable metrics.
To the right is the history graph. We have a graph to the right because it is nice to see the real metrics (not in percentage), it makes it easier to know if the regression is real or not. The history graph is pretty straightforward. You list the metrics you want and you configure how long back in time you want to graph them. We used to do 30 days (that is really good to see trends) but it was too long to see something when an actual regression was happening. Now we use 7 days.
At the moment we test three URLs on desktop in our synthetic testing. If a regression is larger than 10% on all three URLs, an alert is fired. We test three URLs to make sure the change is across the board and not specific to one URL. 10% is quite high but that gives us confidence that it is a real regression.
You can see all the synthetic alerts we have setup at
https://grafana.wikimedia.org/dashboard/db/webpagetest-alerts.
We also alert on our RUM metrics. We alert on first paint, TTFB and loadEventEnd. We set the alerts on p75 and p95 of the metrics we collect and alert on a 5-30% change depending on the metrics. Some metrics are really unstable and some are better. You can see our RUM alerts at
https://grafana.wikimedia.org/dashboard/db/navigation-timing-alerts.
Next steps
We are working on finding smaller regressions and find them earlier using WebPageReplay and mahimahi in our synthetic testing. For RUM we want to collect more metrics and have better buckets to make it easier to find regressions. If you want to follow our progress, you can do that in our performance blog, I’ll promise we will blog when we have the new setup up and running.
If you want to setup alerts yourself you can do that with sitespeed.io/WebPageTest, check out the alerts documentation, it is actually easy. It’s tuning the alerts that take time.