

The basic premise of a content delivery network (CDN) is straightforward enough. We (the CDN provider) become the public face of your website, and with thousands of servers all over the world, end users will connect to a server close to them. If we have the page they want, we give it to them right away, otherwise we go get it from your own servers and remember it for the next user.
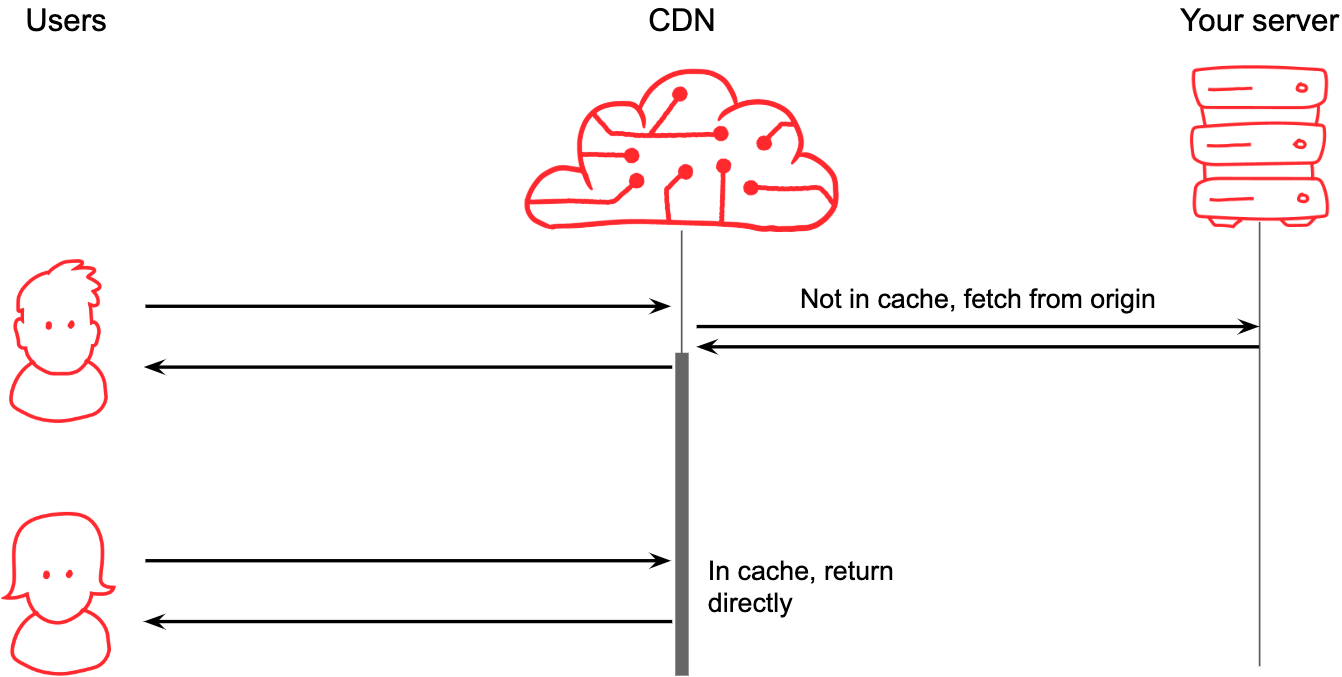
What do CDNs do? Well, you could say it boils down to simply remembering stuff.
But when you’re dealing with millions of requests per second, there’s an awful lot of nuance to how this works. I want to explain one mechanism that makes a huge difference: request collapsing.
The thundering herd problem
While it’s convenient to think about the scenario above where user 1 and user 2’s requests arrive at quite separate times, so that we have the chance to fully serve user 1 before user 2 appears, that’s not really how things work in real life. What actually happens is that user 2 arrives while we are still waiting for the page for user 1:
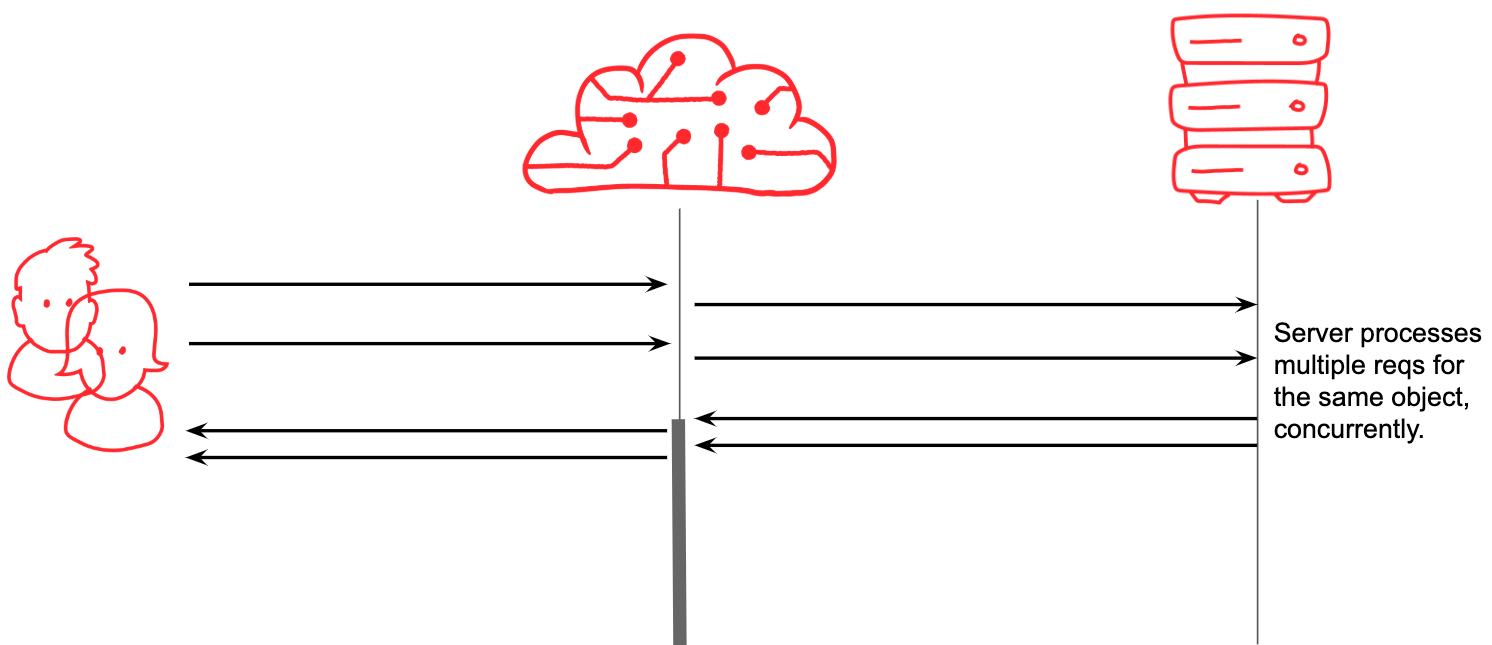
In a naive system, you might forward both of these requests to the origin, as shown above. That would be a bad idea, because, imagining that the page takes 1 second to generate, and you’re getting 1000 requests per second for that page, your origin server might well become overwhelmed trying to do the same thing 1000 times concurrently. So you are humming along quite happily, then the homepage expires in the CDN cache, and suddenly you get slammed.
Queuing
The answer is to have a queue. When user 2 arrives, we know that we’re already in the process of fetching the resource that they want (for user 1), so instead of starting a second fetch, we can attach user 2 to user 1’s request. When the fetch completes, the response can be saved in the cache, and also served simultaneously to both waiting users (and anyone else that’s joined on in the meantime).
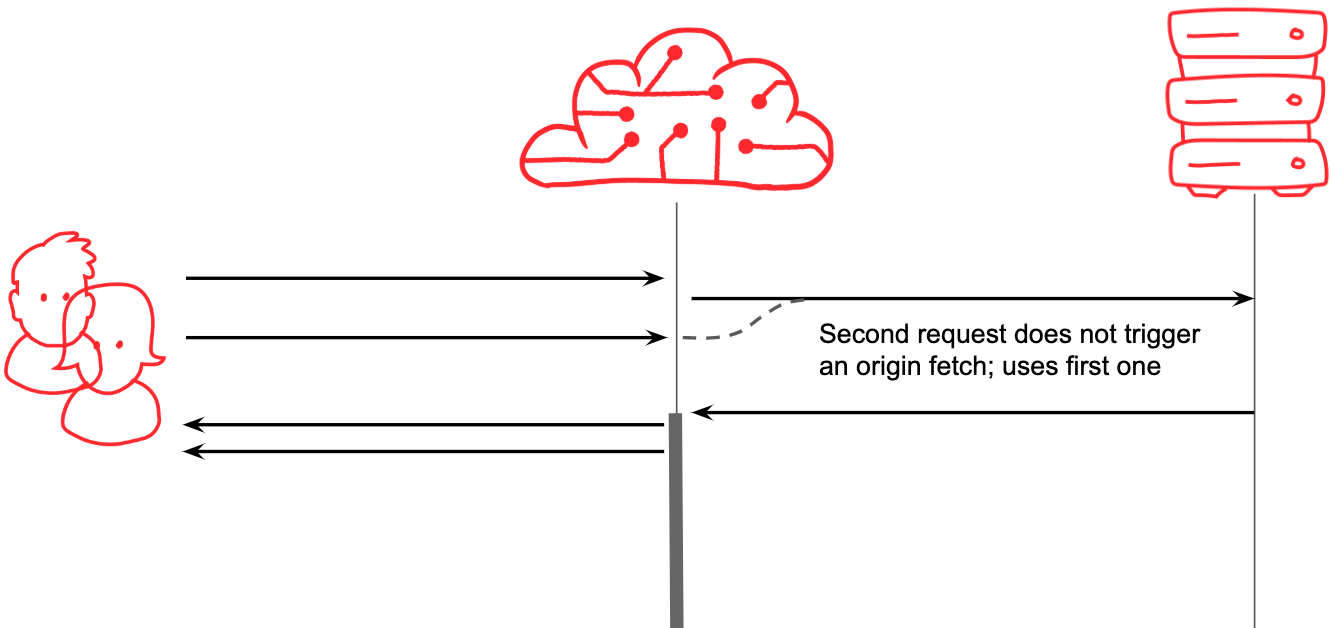
Better. At Fastly we call this solution request collapsing. Most CDNs do something similar. In fact, to get enough scale, we do it in layers: in each data center (sometimes called a ‘point of presence’), multiple collapsible requests that hit the same edge server will be queued on that server, and one request from each edge server will be forwarded to a ‘fetch’ server within the same data center. The fetch server establishes a queue in turn, so that only one request actually escapes the data center to go to your origin.
And of course, there are also multiple data centers, so the CDN will do it between data centers as well, a pattern often called ‘tiering’ or ‘shielding’:
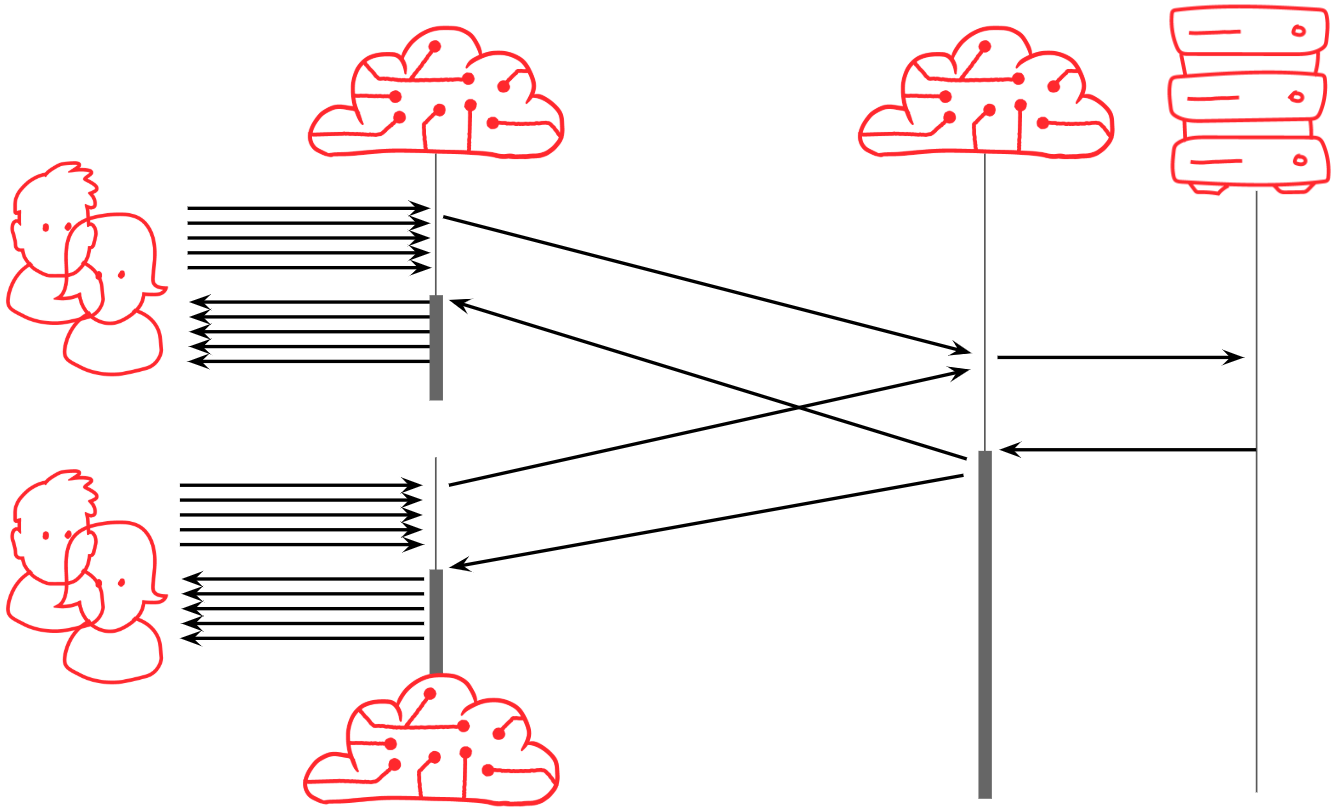
This completes the tree and ensures only a single request ends up knocking on your door.
But what about private resources?
Request collapsing is essential to manage demand for high-traffic resources, but it throws up a ton of edge cases and exceptions that we now have to address. The first and most obvious is what happens if the resource, once it arrives from your origin, is marked private?
Cache-Control: private
As an aside, one of many reasons you should be using Cache-Control and not Expires for your caching configuration is the ability to use directives like private. The private directive tells a CDN that this response is good for only one user, the one that originally triggered the request. Anyone else that got tagged onto the queue must now be dequeued and their requests processed individually:
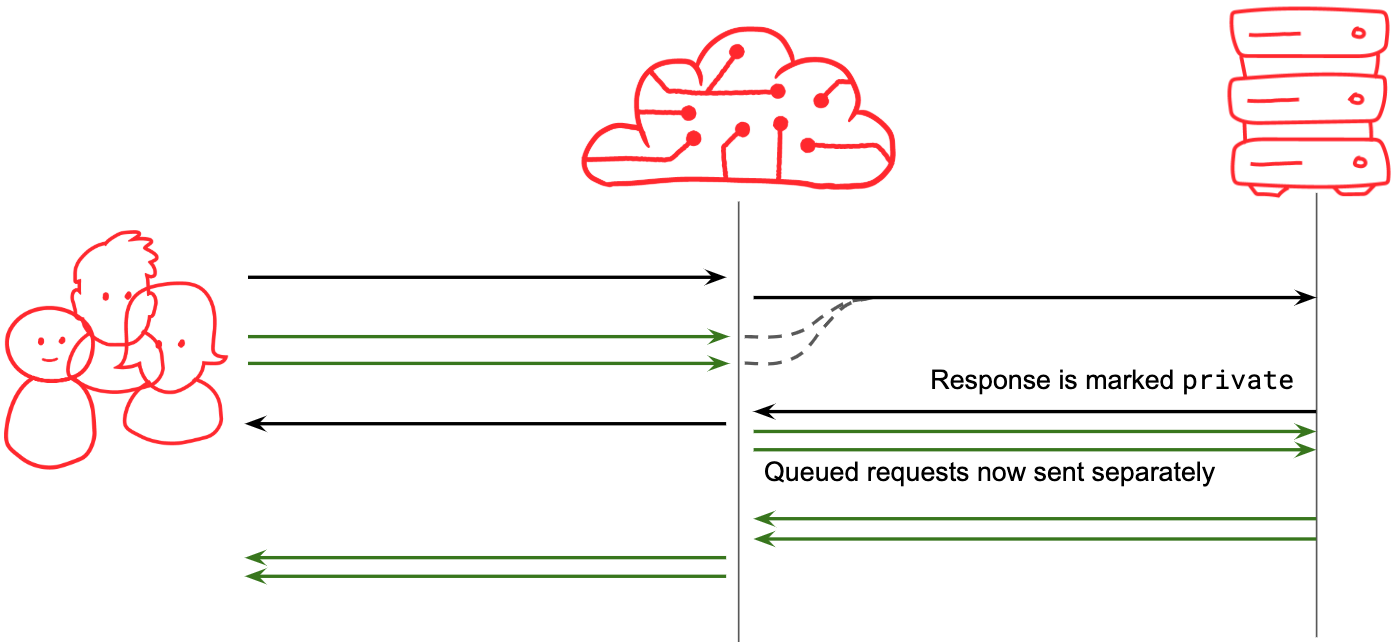
This doesn’t quite solve the problem though. We end up in a cycle. When a private response triggers the queued requests to be dequeued, the waiting requests might well be sent to origin concurrently (at Fastly we do it in batches), but the next request to arrive is likely to start a new queue, resulting in a potentially ‘bursty’ effect on traffic to origin, even if the requests from the clients are arriving at a steady rate:
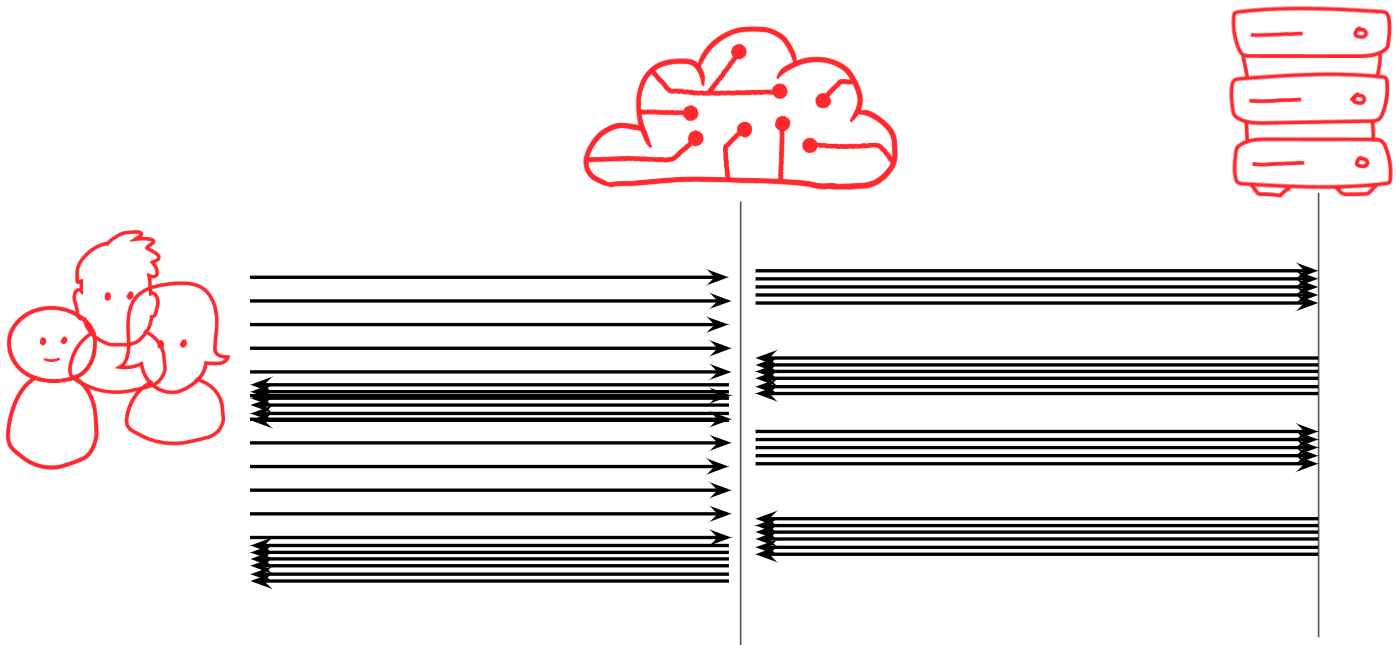
To fix this, a marker can be placed in the CDN cache that says “don’t collapse requests for this resource”. Incoming requests will now hit that marker, and will trigger a fetch to the origin immediately. These marker objects typically live for a configurable interval. At Fastly they apply for 2 minutes by default, and can live for up to an hour. Now the bursty effect is eliminated and queues only form when the marker objects expire.
What about streams?
Up to now, we’ve been considering the potential for an origin server to take some time to generate a response, and what to do with additional requests that arrive while we’re waiting. But this is still an oversimplification – because we assume that when the response does finally arrive, it arrives all at once. That’s not true – HTTP responses arrive in multiple packets, spaced over a period of time, and in the case of large files, slow connections, or streams (e.g. video or sever-sent-events), the response may take a long time to download. What should a CDN do if it receives additional requests for an object whose response has started to be received from origin?
So, first of all, in this situation, we’ve already received the headers, so we know if the response is eligible for request collapsing. If it’s not, we already know we can’t use it for any request except the original one that triggered it. But if it is OK to re-use the response, then depending on the configuration of the CDN, the response might be streamed concurrently to all the clients in the queue, or it might be buffered in the cache and delivered to the waiting clients once the entire response has been buffered.
During this period, if a new request arrives, can it join the party and get access to the partially downloaded resource?
That depends on the caching rules defined on the resource. Resources that are public, but have a low TTL (time to live), e.g. max-age=0, will start streaming to people already on the queue, but requests arriving after the response has started will normally not be able to use it because it is now considered to be expired in the cache, so new requests will initiate a new queue and a new fetch to origin. You will therefore potentially end up streaming multiple copies of the resource from the origin server concurrently.
That might actually be what you want, if the resource is a live stream, and it is of no value to the client to download past data.
Conversely, if the resource is cacheable, e.g. max-age=60, then additional requests arriving during that window will join on to the existing response. For a stream that is being delivered slowly, that means the data received so far will be sent to the new client very quickly, and once they have ‘caught up’, they’ll then be in sync with all the other clients receiving the stream.
Why do I need to know all this?
OK, so this is all very interesting, but in practice who really needs to know that this happens? Well, one big gotcha that can cause serious problems with sites introducing CDNs is not understanding that responses that are ‘not cacheable’ can still be collapsible. If you believe you are serving a response to a single user, e.g. a cart or an inbox listing, make sure it is marked as private. Directives like no-cache and no-store do not prevent request collapsing, though some CDNs might take those directives as hints to disable collapsing.
It is also worth thinking about whether you want your CDN to buffer responses or stream them. Request collapsing in conjunction with streaming responses offers the opportunity to “fan out” a single response stream to a large number of clients.
However you make use of it, request collapsing is pretty fundamental to making the web work efficiently, and we’re all better off because of it.