

Alex Russell (@slightlylate) is Partner Program Manager on the Microsoft Edge team and Blink API OWNER. Before joining Edge in 2021, he worked on Chrome's Web Platform team for a dozen years where he helped design many new features. He served as overall Tech Lead for Chromium's Project Fugu, lead Chrome's Standards work, and acted as a platform strategist for the web. He also served as a member of ECMA TC39 for more than a decade and was elected to three terms on the W3C's Technical Architecture Group.
His technical projects have included Fugu, Progressive Web Apps, Service Workers, and Web Components, along with ES6 features like Classes and Promises. Previously he helped build Google Chrome Frame and led the Dojo Toolkit project. Alex plays for Team Web.
In a recent Perf Planet Advent Calendar post, Tanner Hodges asked for what many folks who work in this space would like for the holidays: a unified theory of web performance.
I propose four key ingredients:
- Definition: What is “performance” beyond page speed? What, in particular, is “web performance”?
- Purpose: What is the purpose of web performance as a discipline? What are its goals?
- Principles: What are this discipline’s guiding principles?
- Practice: What does it look like to practice web performance? How do we do it?
This is a tall order!
It incorporates a hope for a baseline theory as well as doctrine and practicum. Hopefully, the community can organise the latter once we roughly agree on a socio-technical view of what web performance is and what it’s for. To make a general theory practical, leaders in the community will need to translate and connect principles to outcomes.
This Is For Everyone

Tim Berners-Lee tweets that ‘This is for everyone’ at the 2012 Olympic Games opening ceremony using the NeXT computer he built the original browser and web server on.

Embedded in the term “web performance” is the web, and the web is for humans.
That assertion might start an argument in the wrong crowd, but 30+ years into our journey, all attempts to imagine and promote a different first-order constituency are generally considered failures. As the Core Platform Loop predicts, this makes economic sense. The web ecosystem grows or contracts with its ability to reach people and meet their needs safely and with low friction.
Taking seriously the idea that “this is for everyone”, the contours of ethical and aspirational goals for web performance emerge. Performance, for the marginal user, is the difference between access and exclusion.
The mission of web performance is to expand access to information and services on the web.
Page Load Isn’t Special
It may seem that web performance comprises two separate disciplines:
- Optimising page load
- Optimising post-load interactions
The tools used by performance investigators in each scenario have some overlap but generally feel like separate concerns. The metrics that we report against implicitly cleave these into different “camps”, leaving us thinking about pre- and post-load as distinct universes.
But what if they aren’t?
Consider the humble webmail client.
Here’s Gmail rendering the same inbox in two architectural styles: Ajax-based and “Basic HTML”:
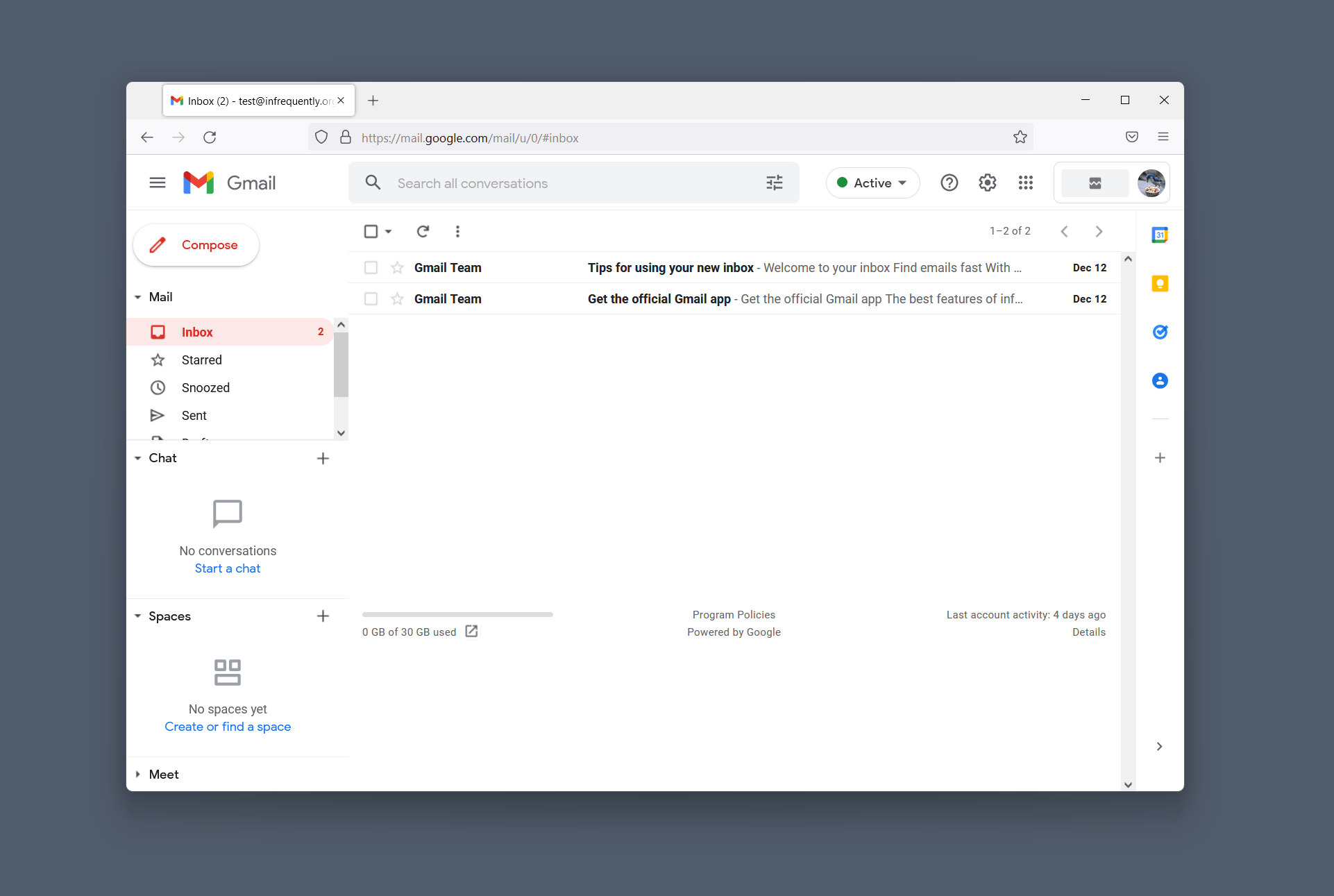
The Ajax version of Gmail loads 4.8MiB of resources, including 3.8MiB of JavaScript to load an inbox containing two messages.
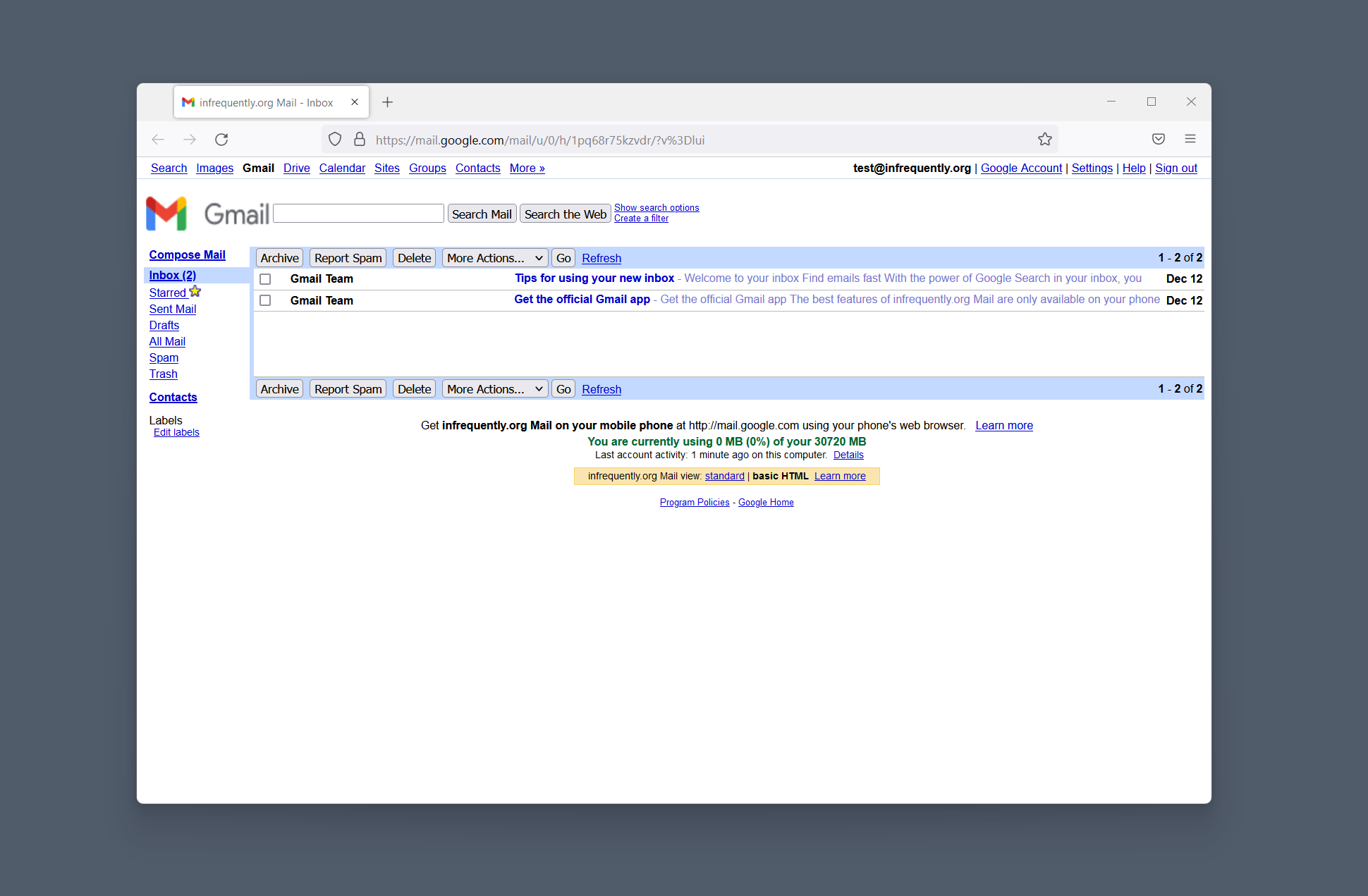
The ‘Basic HTML’ version of Gmail loads in 23KiB, including 1.3KiB of JS.
The order-of-magnitude increase in weight to begin to interact with one’s email between these versions is interesting, but what we should focus on most is the per interaction loop. Typing gmail.com, hitting enter, and eventually returning to a state in which one can take a further interaction is effectively the same interaction. One of these is better, and it isn’t the experience of the “modern” style.
Central to any generalised understanding of web performance are the steps we just experienced in navigating to an inbox:
- The system is ready to receive input
- Input is received and processed
- Progress indicators are displayed
- Work starts, progress indicators update
- Work completes, output is displayed
- The system is ready to receive input
Consider the next tap in our journey; opening the first message. The Ajax version leaves most of the UI of the application in place, whereas the Basic HTML version conducts a full page reload. The chief effect of this difference is to shift the distribution of latency within these steps. Regardless of architecture, Gmail needs to send an HTTP request to the server and update some HTML when the server replies.
Some folks frame performance as a competition between the Team Local (steps 2 & 3) and the Team Server (steps 1 & 4). Today’s web architecture debates (SPA vs MPA, e.g.) embody this tension.
Team Local values heap state because updating a few kilobytes of state in memory can, in theory, involve less work in returning to interactivity (step 5) and improve the experience of steps 2 and 3 in the process.
Intuitively, modifying a subtree of the DOM should generate less CPU load and network traffic than tearing down the entire contents of a document, asking the server to compose a wholly new one, and then parsing/rendering the resulting document and all of its subresources. Successive HTTP documents on sites tend to be highly repetitive, after all, with headers and footers and shared elements continually re-created from source on each navigation.
But is this intuitive understanding correct more often than not? And what about the other benefits of avoiding full page refreshes, like the ability to animate smoothly between states?
Herein lies the source of our collective anxiety about frontend architectures: traversing networks is always fraught, but the costs to deliver client-side logic to cushion users from variable network latency remain stubbornly high. Improving latency for one scenario can degrade it in another. Despite the protests of partisans, there are no silver bullets, only complex tradeoffs that must be grounded in real-world contexts. In other words, engineering.
As a community, we aren’t very good at naming or talking about the distributional effects of these impacts. Performance engineers have a fluency with histograms and percentiles that the broader engineering community could benefit from as a lens for thinking about the impacts of design choices.
Given the last decade of growth in JavaScript payloads, it’s worth resetting our foundational understanding of these relative costs.
Here, for instance, are the network costs of transitioning from the inbox view of Gmail to the display of a message:
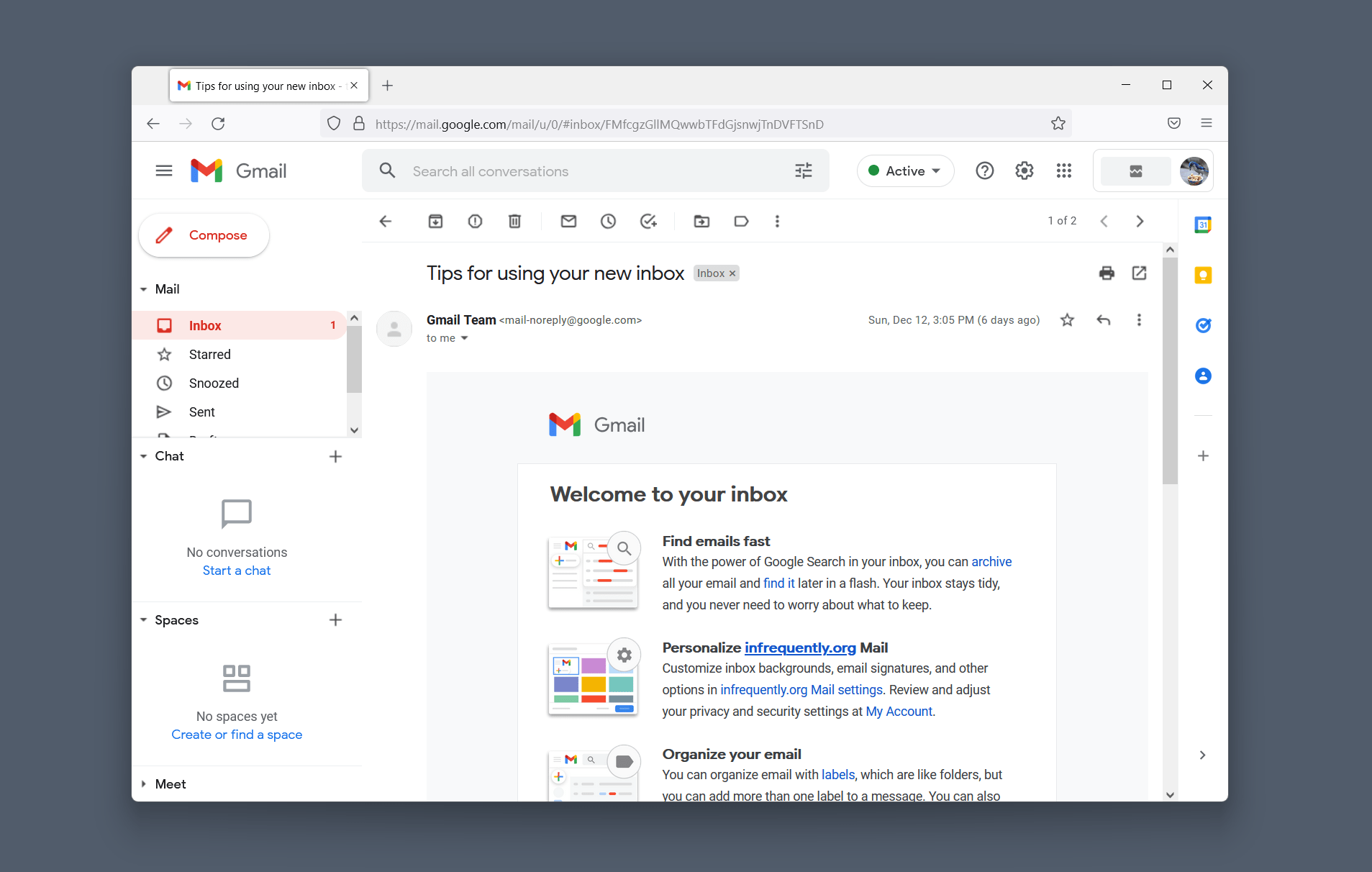

Displaying the first message requires 82KiB of network traffic in the Ajax version of Gmail, half of which are images embedded in the message.
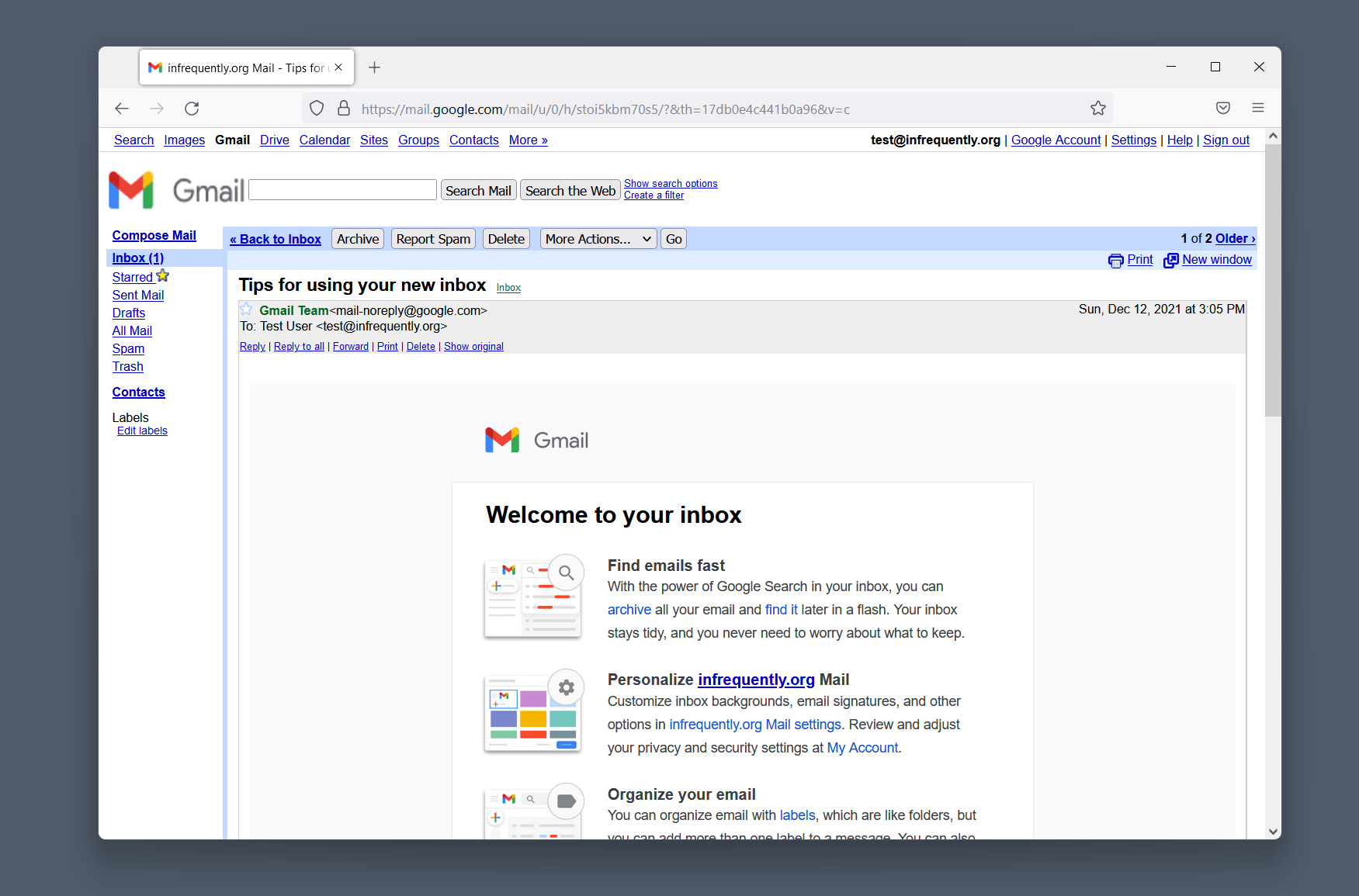
Displaying a message in the ‘Basic HTML’ version requires a full page refresh.
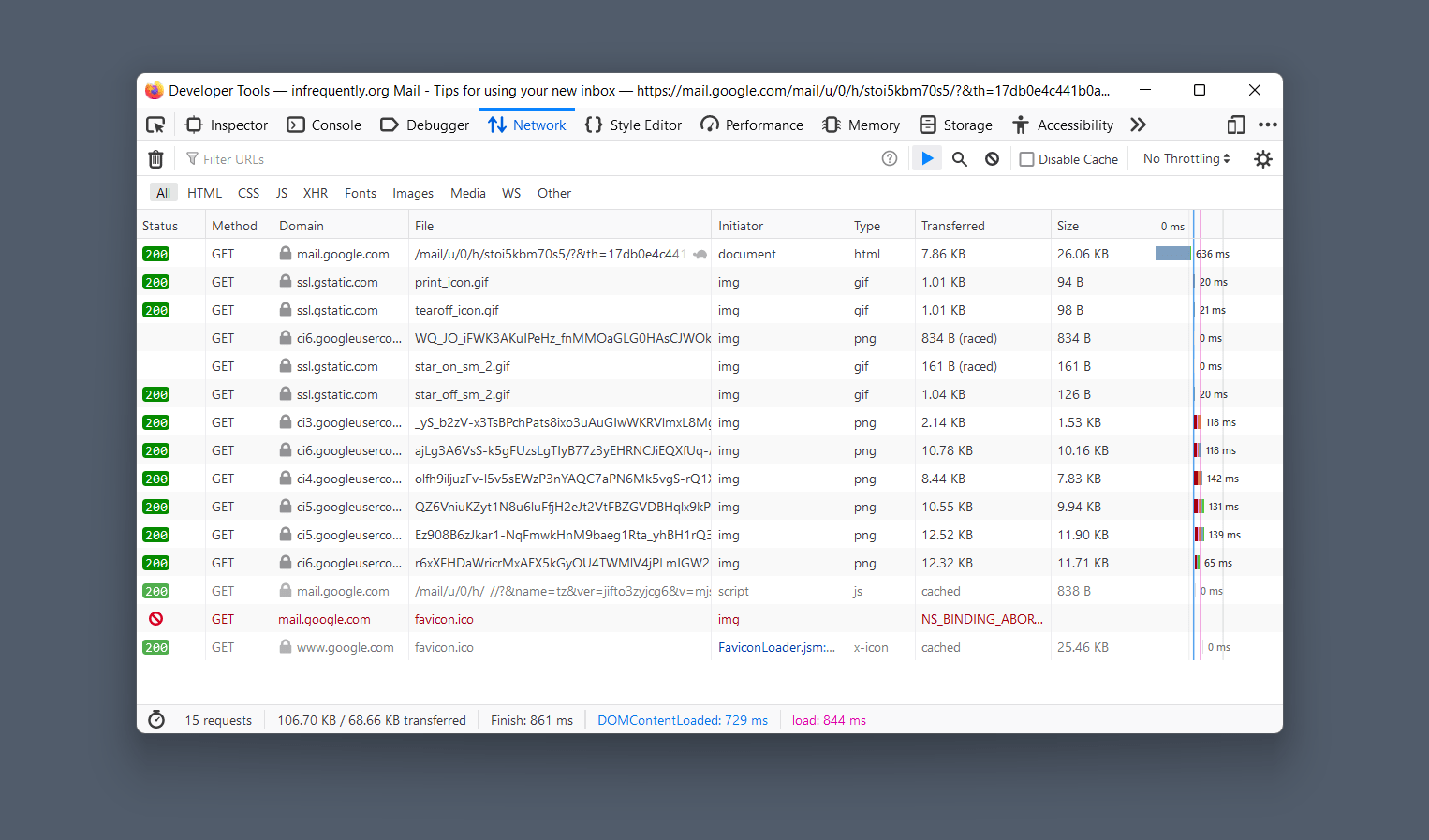
Despite fully reloading the page, the HTML version of Gmail consumes fewer network resources (~70KiB) and takes less time overall.
Objections to the comparison are legion.
First, not all interactions within an email client modify such a large portion of the document. Some UI actions could be lighter-weight in the Ajax version, mainly if they operate exclusively on client-side state. Second, but avoiding a full-page refresh, states 2, 3, and 4 in our interaction loop can be communicated with greater confidence and in a less jarring way. Lastly, by avoiding an entire back-and-forth with the server for all UI state, it’s possible to add complex features like Chat and keyboard accelerators in a way that doesn’t incur context and focus loss.
The deeper an app’s session length and the larger the number of “fiddly” interactions a user may perform, the more attractive a large up-front bundle to hide future latency can be.
This insight gives rise to a second foundational goal for web performance:
We improve performance by reducing latency and variance across all interactions in a user’s session to return the system to an interactive state more reliably.
For sites with low interaction depths and short sessions, this implies that web performance engineering might remove as much JS and client-side logic as possible. For other, richer apps, performance engineers might add precisely this sort of payload to reduce session-depth-amortised latency and variance. The tradeoff is contextual and informed by data and business goals.
No silver bullets, only engineering.
Medians Don’t Matter
In the realm of histograms and percentiles, not all improvements are equal.
We now understand our goal to minimise latency and variance in the interactivity loop…but for whom? Going back to our first principle, we understand that performance is the predicate to access. This points us in the right direction. Performance engineers across the computing industry have learned the hard way that the sneaky, customer-impactful latency is waaaaay out in the tail of our distributions. Many teams have reported making performance better at the tail only to see their numbers get worse upon shipping improvements. Why? Fewer bouncing users. That is, more users who get far enough into the experience for the system to boot up enough to report that things are slow (previously, those users wouldn’t even get that far).
Tail latency is paramount.
Web performance engineers improve latency and variance at the tail of the distribution first and foremost because that is how we make systems accessible, reliable, and equitable.
A Unified Theory
And so we have the three parts of a uniform mission or theory of web performance:
- The mission of web performance is to expand access to information and services on the web.
- We do this by reducing latency and variance across all interactions in a user’s session to return the system to an interactive state more reliably.
- To accomplish this, we work to improve the tail of the distribution because that is how we make systems accessible, reliable, and equitable.
Perhaps a better writer will find a pithier way to encapsulate these values. Still, they are my north star in performance work and serve to unify the many tensions in directing investigative and remediation work. Focus on getting back to interactive for those least enfranchised, at the tail of the distribution, and the rest will work itself out.