

Tim Vereecke (@TimVereecke) loves speeding up websites and likes to understand the technical and business aspects of WebPerf since 15+ years. He is a web performance architect at Akamai and also runs scalemates.com: the largest (and fastest) scale modeling website on the planet.
This blogpost covers how I used a Distributed Architecture (Cloud+Edge) to beat latency for the global user base of scalemates.com (largest scale modeling platform in the world)

The Problem
At first glance my CrUX data (Via treo.sh) indicates I should rather watch Netflix instead of further tuning performance!
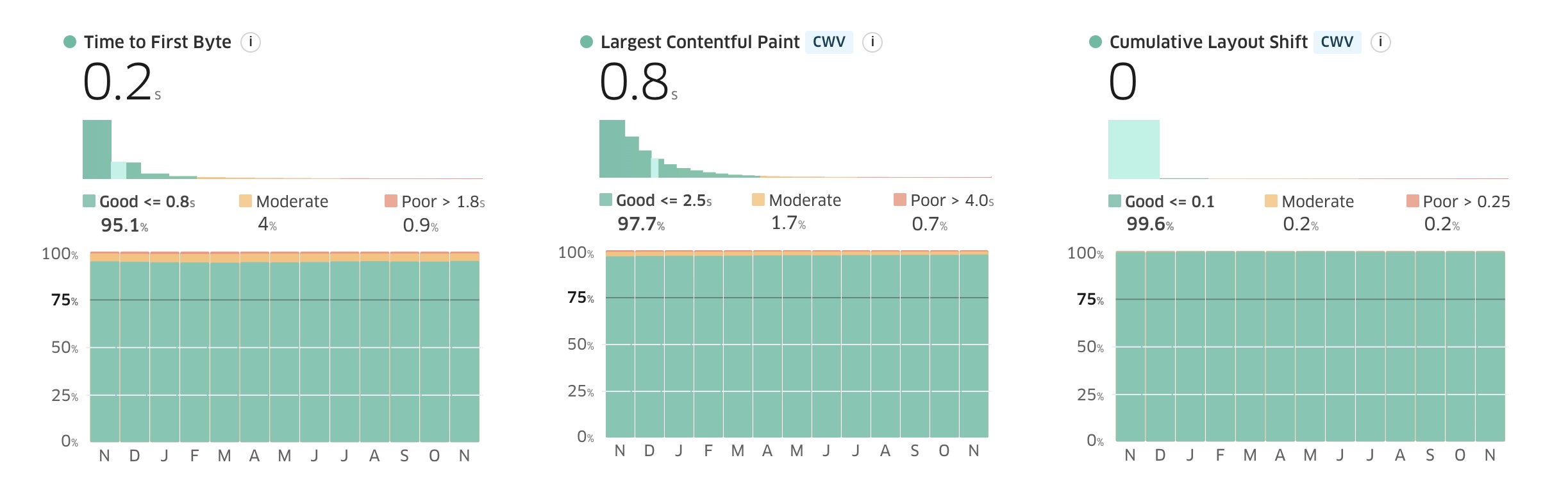
When we zoom in on Waiting Time (aka Server think time) by Country we see that the sky isn’t always blue.

The above Real User Monitoring (mPulse RUM) data shows that countries further away from my origin in Frankfurt (Germany) are seeing degraded performance due to increased latency.
While for the US and Canada it is still reasonable, for my Australian and Japanese visitors it is painful!
End users don’t care about Waiting Time, but Waiting time is a key contributor to TTFB which is again a key contributor to Largest Contentful Paint (LCP. If you speed up Waiting Time you speed up LCP!
Original Setup
A high level diagram of my original setup shows a single Data Center in Frankfurt fronted with my CDN. The origin runs Nginx/PHP/MariaDB in combo with Solr search engine. A well tuned PHP application with the help of Memcached generates pages within a few milliseconds. The CDN config contains all 2022 best practices and shaves of milliseconds wherever possible.

I am a big proponent of CDN caching to reduce latency but my content is very volatile and has an extremely long tail.

- Long tail: Scalemates.com has 900K product detail pages translated into 16 languages. I frequently run A/B experiments with 2 variations. This alone results in 28.800.000 variations.
- Volatile:
- 3 Million “live” Price and stock info from 50+ online shops changing frequently
- 40-60K Monthly edits to the product database by contributors
- (40+ deployments a month)
With 6 Million monthly pageviews it is not a small site. However there are only 200K daily pageviews for 28M variations.
Hence caching for a large amount of requests is here not THE solution.
The Solution
I deployed replicas of my application in regions currently seeing the highest latency issues. (Tokyo, Sydney, Atlanta)
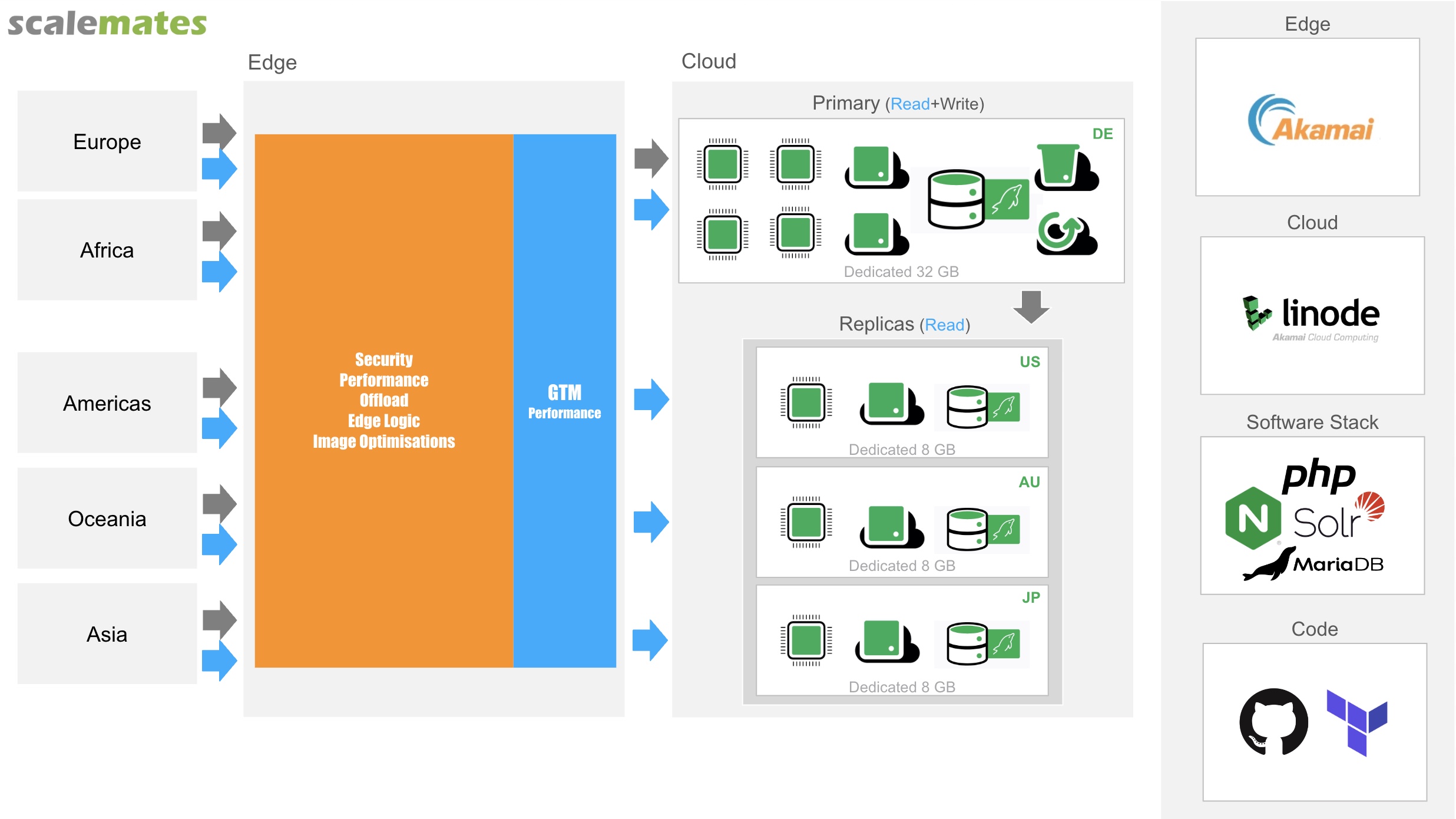
Using standard MariaDB replication the replicas stay all in sync with the primary in Frankfurt.
Replicas are kept lightweight as they don’t run all heavy services and maintenance jobs of the primary.
In order to Route relevant traffic to the right DC I do the following:
- Identify Product Detail Pages (Path Match)
- Identify Guests (Check value of a cookie)
- Override the default Frankfurt Origin with an Global Traffic Management (GTM) DNS entry

In the above screenshot the origin uses a dynamic perf.satelites.scalemates.com.akadns.net DNS entry. This GTM entry resolves to the closest working Data Center.

Using a tool like dnschecker.org we see that the GTM entry resolves differently based on the location.
Monitoring
Once a replica is live I can validate if traffic is flowing as expected based on GTM reporting.

To validate that my performance is as fast as expected I created a custom dimension in RUM. This dimension tracks the DC the request was served from.
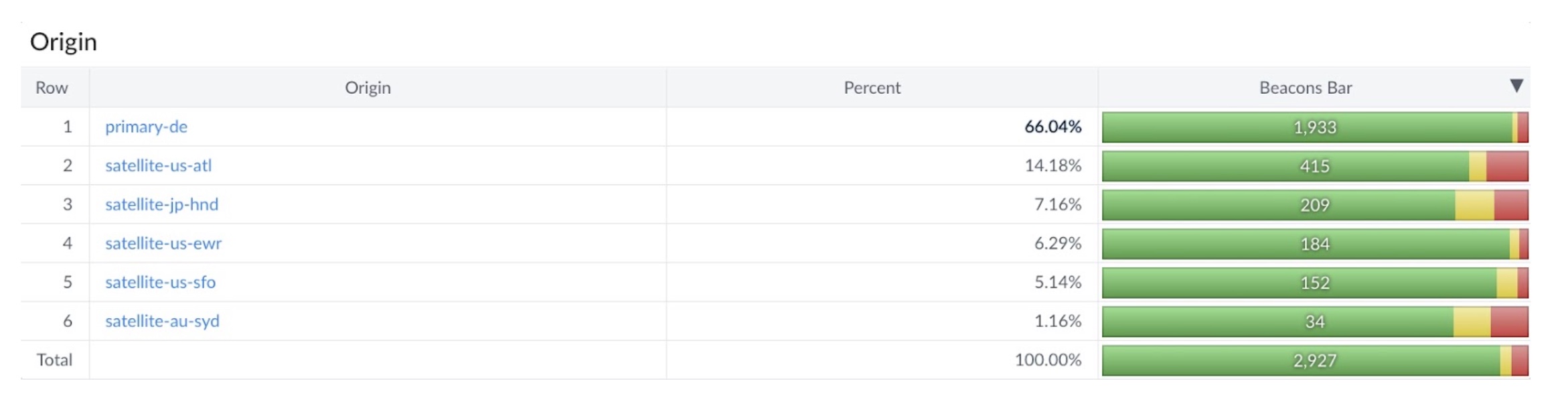
This allows to granularly capture:
- Performance degradations
- Load imbalancing
- Downtime
- Opportunities for new DC locations
Results
Here you see the overall impact while I gradually rolled out additional Data centers in November 2022.
All percentiles show a performance improvement: 95P (blue), 75P (pink), Median (Orange), 25P (Dark blue) and 10P (Green)
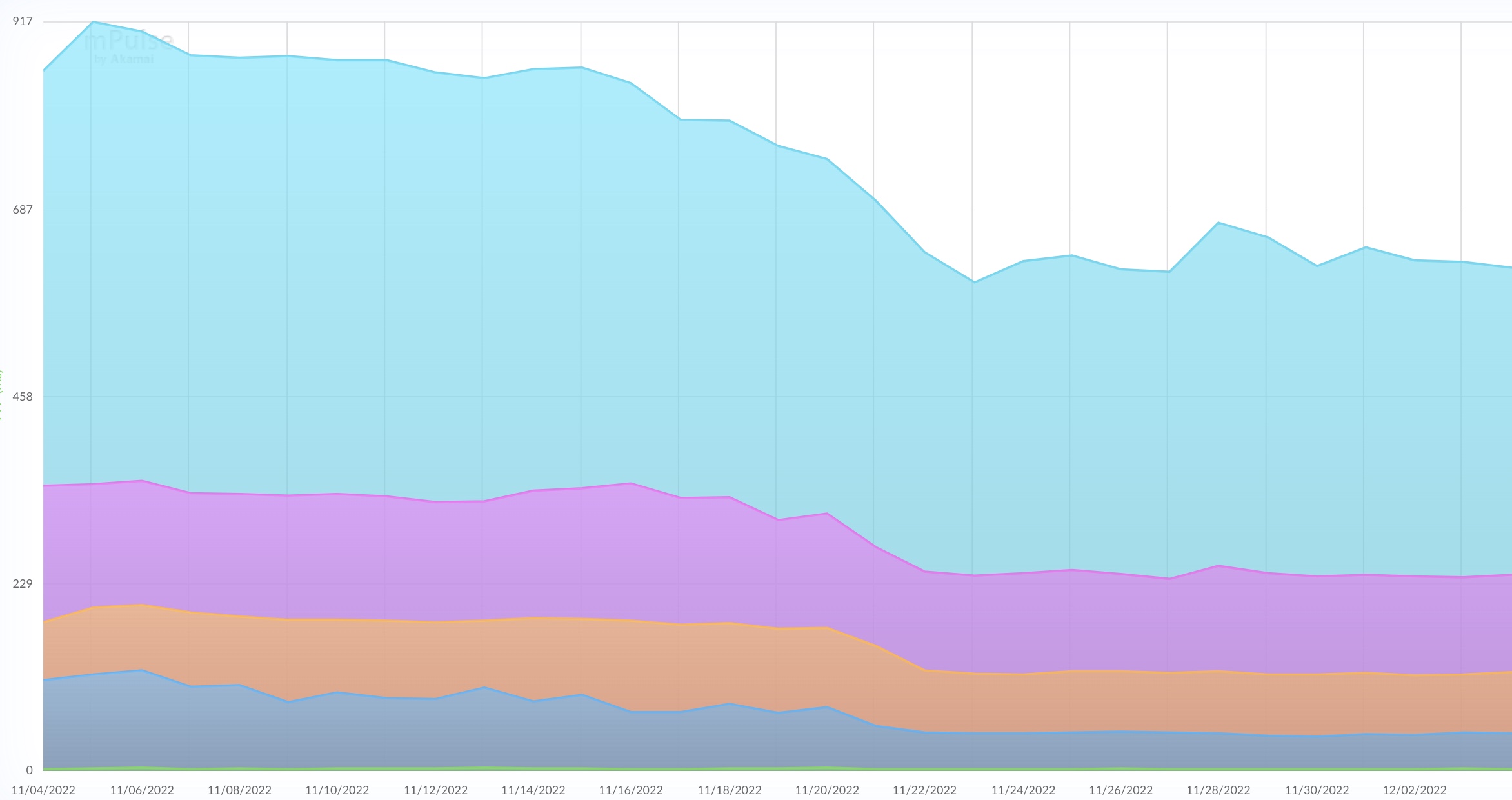
Specifically for Australia (see below) the result was exceeding expectations.
Extra comments
Automation
If you plan to run multiple instances globally a manual approach is definitely out of the picture.
At a high level I used Terraform to provision both Cloud and Edge components of the infra:
- Compute Instances
- Global Traffic Management
- CDN settings
- Network Firewalls
Several bash scripts are available to automate repetitive tasks:
- Initialisation (Restore from latest backup, Account creation, Deploy SSH Keys, copy TLS certificate)
- Deploy scripts (PHP code, cronjobs, maintenance scripts)
- Restart scripts (Restarting every 7 days works to avoid long term issues)
- Purging (Memcached on servers and CDN cache)
Future considerations
My architecture is not limited to a single cloud vendor. I can easily mix and combine multiple cloud providers based on their regional presence, performance and cost.
In the near future I will likely add extra replicas in:
- Brasil
- South Africa
- Canada
- Singapore
Summary
In order to beat latency you should first try to cache at the CDN.
If that does not work you can bring your origin closer to the end users. If that is Cloud, at the Edge or a mix depends on your application.