

TLDR;
- We have conducted web performance research at the University of Hamburg since 2010.
- We came up with a approach to cache dynamic website resources like HTML and APIs which can be plugged into websites via Service Workers
- automatically dealing with personalization in HTML
- keeping caches up-to-date by crowdsourcing cache checks
- caching dynamic resources in the complete web cache hierarchy including browser cache through Bloom filter-based cache coherence algorithms
- adding lots of other optimizations like predictive preloading, 3rd-party caching and image optimization
- Impact on Core Web Vitals can be A/B tested and measured via RUM on production traffic
- Large-scale e-commerce pages show best performance improvements
Targeting large gains in web performance
Twelve years ago we started our research on web performance and caching of dynamic content with the goal to make the web a much faster place.
In this post we share the results of this journey and explain how the approach enables large performance gains A/B tested and measured with Real User Monitoring like the one in the chart below.
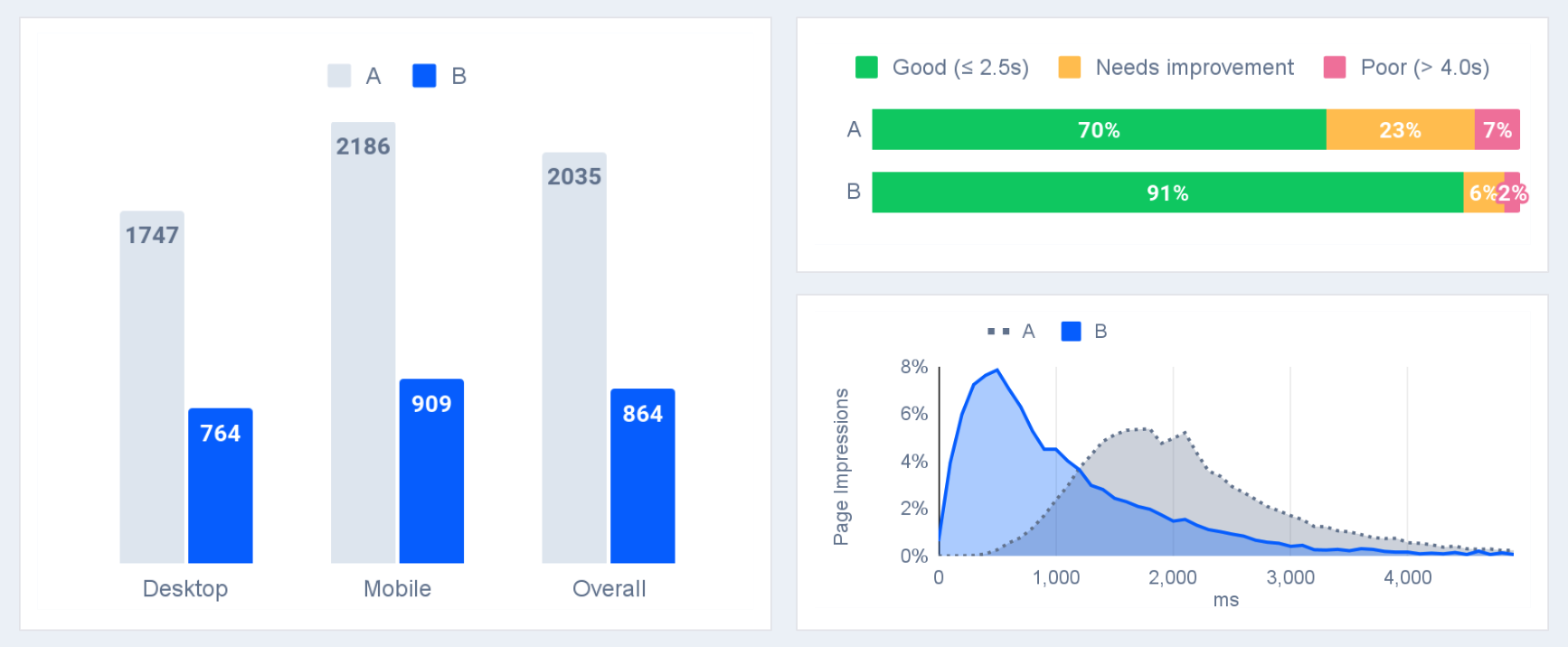
Largest Contentful Paint comparison from an A/B test measured via Real User Monitoring (RUM).
References to scientific publications are scattered throughout the article but for a comprehensive list you can scroll down to our publications list at the very end.
Bottlenecks in modern web performance
On a high level, all pages on the web load in the same way and experience the same sources of performance bottlenecks.
Let’s start with the basics here, to better highlight what changes about the page loading process when Service Worker is used. If you are a web expert feel free to skip to the next section.
On a high level, loading a website is very simple:
- The client requests the HTML resource.
- The server generates a response and sends it to the client.
- The client loads linked resources like CSS, JS, images and other assets.
- The browser compiles and executes JavaScript code and renders the page.
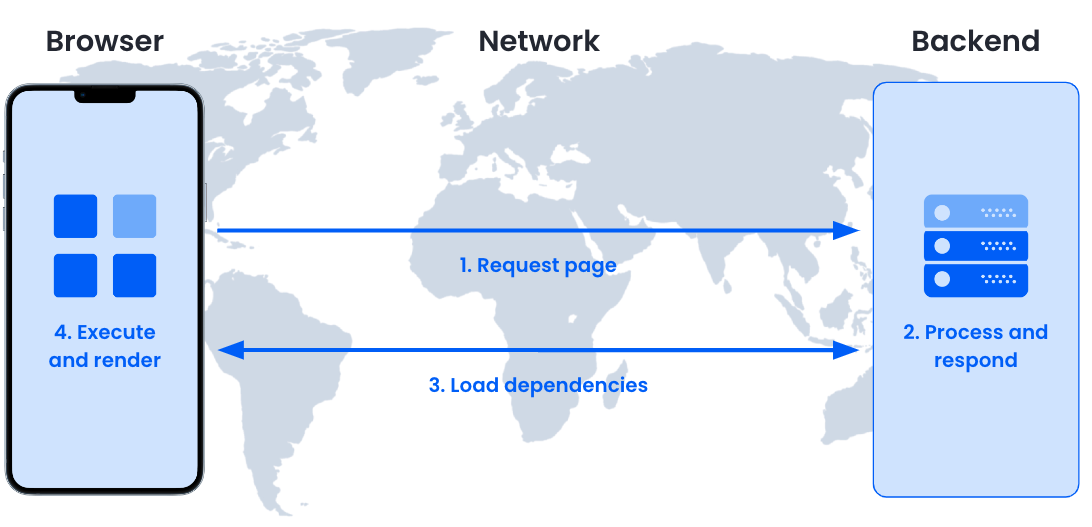
A simplified diagram of how web pages are loaded
These steps also make up the main performance bottlenecks; or to frame it more positively, they highlight the common areas of optimization:
- Improve the first request with protocol optimizations (fast DNS, 0 round-trip TLS, OCSP stapling, HTTP/3).
- On the backend, try to keep processing overhead to a minimum, optimize database queries and slow code paths, and use caching wherever possible.
- Keep your critical rendering path (CRP) as short as possible by reducing the number of bytes sent over the network and avoiding render- or parser-blocking resources.
- Keep the frontend “lean”, render the page without executing JavaScript, use efficient CSS and avoid layout shift.
Most likely any company operating a website has lots of optimizations like these in their backlog, some being harder to implement than others.
With our research we went a slightly different route and did not try to solve all of a website’s bottlenecks individually. Instead we use a Service Worker and special caching mechanisms to change how the browser loads the page.
Accelerating Dynamic Resources: How it works
In contrast to traditional caching solution implemented on an infrastructural or backend level, we will come in on the client side and optimize how the browser loads the page and how it makes use of available caches. This also means there are no changes to the backend, frontend or infrastructure required at all.
The optimisation can be applied just by hosting and installing a special Service Worker. Once activated, the service worker runs in a background thread in the user’s browser and acts as a network proxy, seeing every request that the browser sends to the network. Service workers are supported in 97% of browsers, do not require permission to be used, and are completely invisible to users.
We will use the service worker to reroute requests to a distributed caching network, shown as Caching service in the graph below. The unique part here is that not only static files like JS, CSS and images are cached, but also dynamic resources like APIs or HTML that can change at any point in time.
For HTML resources, we need to ensures that personalized content (e.g. login state, recommendations, cart) is still loaded from the original website servers. We also need to automatically keep the cached content up-to-date and finally enables caching of these dynamic resources on every level of the cache hierarchy including the user’s device itself.
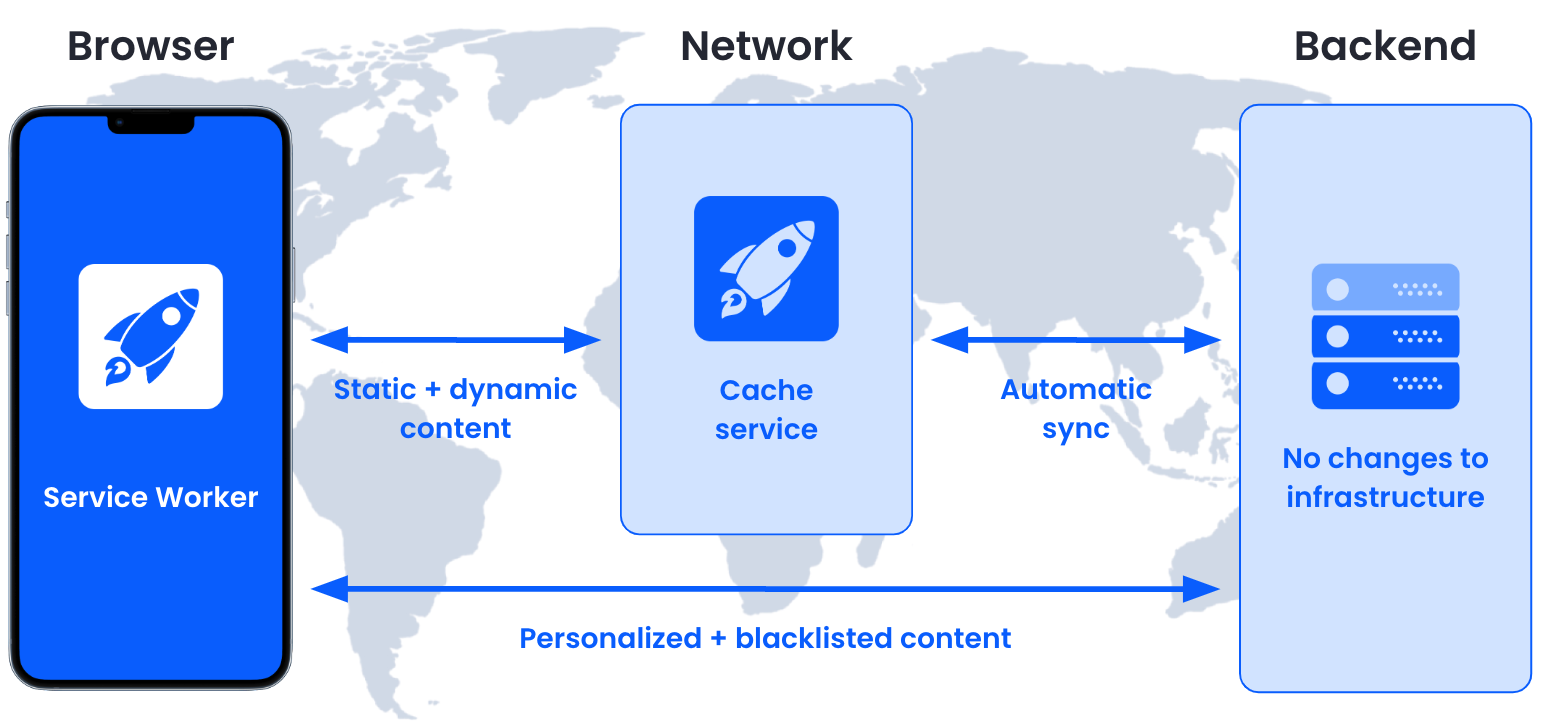
Caching Architecture
Caching HTML resources of websites in a generic way is quite a complex task — for e-commerce pages in particular — and we are faced with three main challenges:
- How can HTML be cached if it is personalized?
- How can caches be kept up to date for millions of pages when content changes unpredictably?
- How can dynamic content be cached in the client without an API to purge it?
The next three sections cover how we tackle those three challenges.
Challenge 1: Caching personalized content
Personalization and caching are usually not compatible since multiple users cannot receive the same cached response without losing their personalization. So HTML that contains personalization is generally considered uncacheable.
That said, in most scenarios only parts of a page’s content are personalized and large sections look the same for all users. A good example for this is product detail pages on e-commerce platforms where prices, recommendations or the cart icon may be personalized, but the product image, title and description are the same for all users.
We are using this fact to our advantage and load personalized (non-cachable) and common (cacheable) parts separately by changing how the browser loads the initial HTML. In e-commerce in particular, the common part usually contains important information for the user that needs to be loaded as fast as possible.
The loading process works like this and is shown here:

The Service Worker requests two versions of the HTML document
- A user navigates to a page
- The Service Worker issues two requests in parallel that race each other:
- One request is sent to the Caching service, loading an anonymous version of the page. The request does not include any cookies or session information and the page is the same for all users and therefore cacheable. It is the one you would see if you opened the page in an Incognito or private tab.
- The other request is sent to the origin backend. It contains all usual cookies and returns the personalized page tailored to the exact user.
- Usually, the cached HTML response is much faster and wins the race. The browser receives the HTML and can immediately start loading all the dependencies and render the anonymous page.
- Once the backend response from the origin server with the personalized HTML is received, it is merged with the already-rendered HTML and the personalized sections of the page become visible. To the user, the personalized parts are progressively rendered.
While the process does incur the overhead of loading two full HTML files containing redundant information, it usually renders personalized content faster than loading it via fetch requests from JavaScript since the request for personalized content is issued in parallel to the initial HTML request.
There are a lot of important details to how this merging of two HTMLs in the browser works and how it can be tweaked which goes beyond the scope of this blog post. For example, content merging can introduce flickers and shifts which can then be fixed via CSS.
The most important challenge of how this works with JavaScript or even modern frontend frameworks however will be addressed in the next section.
Challenge 1.1: Delaying JS to avoid problems from merging personalized content
As explained in the previous section, applying personalization requires to merge the personalized HTML into the already rendered anonymous HTML in the browser which involves exchanging DOM nodes.
While the browser is very efficient in only rendering things that have changed, JavaScript is not so forgiving of sudden changes in the DOM nodes. Event listeners might break, click listeners might not be attached any longer, client-side-rendered elements might disappear and the shadow DOM of frameworks like React or Vue adds another layer of complexity.
To prevent JavaScript from breaking, the only option is to delay it until the personalized HTML is merged and no unexpected DOM changes can appear. Afterwards the JS execution can continue.
The following gif shows how requesting and merging two HTML files plays together with delaying the JS execution.

The details on how JS is delayed are very important to ensure correct execution and good performance. This is how we deal with this challenge:
- The cached HTML needs a few preparations that are applied automatically:
- The code responsible for merging the personalized HTML document is inserted at the end of the
body. - Since the code insertion happens asynchronously, we then place a blocking external script after that to pause JS execution until after the document merge.
- Next, all external scripts are re-inserted after the blocking script, preserving their order. All inline scripts are removed (they tend to contain personalization and need to be executed from the personalized HTML).
- An inline script is placed before each external
scripttag that executes all inline scripts from the personalized HTML.
- The code responsible for merging the personalized HTML document is inserted at the end of the
- Once the cached HTML is handled by the browser and the parser get towards the end of the body it will detect the blocking script and request it. As long as that request is pending, JS execution cannot continue.
- The Service Worker will receive that special JS request and withhold the response.
- Once the code for merging the personalized HTML into the rendered document has completed, it sends a message to the Service Worker.
- On receiving the message, the Service Worker responds to the pending script request with an empty script causing the JS execution to continue normally.
- The inline script between the external script now have access to the personalized HTML and can simply insert and execute the inline script in the correct order.
Delaying JS execution through this approach has some important advantages. Firstly, it prevents DOM events like domInteractive or domContentLoaded from firing before the actual JS is executed. Secondly, since the external scripts are in the cached document already, the preload scanner of the browser will discover them early, then download and compile them for faster execution. Thirdly, personalized or dynamic inline scripts that are very common in e-commerce applications are easily covered by this.
This approach enables caching even of personalized HTML pages. The next two challenges are important optimizations independent of whether the HTML is personalized.
Challenge 2: Automatic cache sync via Change Detection
Not only is personalization a challenge when caching dynamic resources like HTMLs or API responses; even the anonymous version of the main document can change at any point in time, making it necessary to update caches accordingly. With potentially millions of cache entries necessary, this is a big challenge.
We will tackle this challenge with a concept called Change Detection. It builds on the mechanism used for personalization to detect changes to the page.
Since every user loads both the anonymous cached version of the HTML as well as the personalized version from origin, we already have everything we need to validate the cache entry on the client side. If something in the cached version has changed, we inform the Cache service, which refreshes the resource and updates the caches only if the content has actually changed.
As an example: let’s say someone changes the product title for a product detail page in the CMS. The cached version of the page will contain the old product title and is no longer up-to-date. When a user navigates to the product page, they receive the stale cache entry with the old title. Once the personalized HTML with the new product title arrives in the browser, the versions are merged and the new product title appears. As both HTML versions are compared, a cache refresh is triggered because of the changed title.
The first user to detect the change will experience a flicker of the title when the up-to-date title appears upon merge. All other users and even the first user upon reload will not experience that flicker and receive an up-to-date cached version. This effectively crowdsources the challenge of discovering outdated cache entries among millions of cache entries without increasing the origin server load.
Additionally, we use the “cache hotness” information from our shared caches to sample the change detection on frequently-visited pages to reduce overhead.
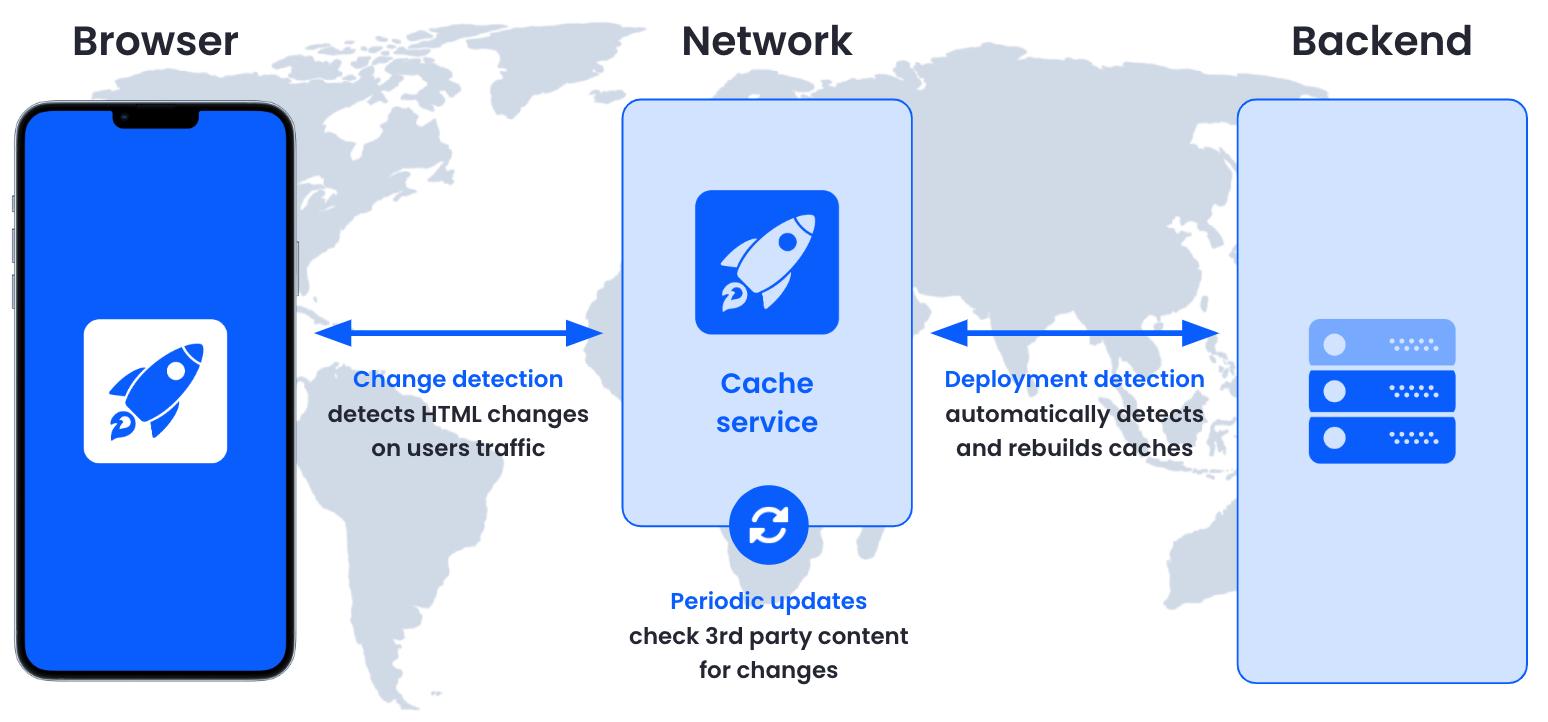
Cache synchronization is crowdsourced through “Change Detection”
Deployments of the whole application are treated separately from page-level difference because they can result in structural changes that make it impossible to merge the cached version with the new original version. We can handle new deployments in a process called Deployment Detection: If the site links new JS and CSS versions, the Cache services infers that a deployment was rolled out so it can purge the entire cache and rebuild it asynchronously.
The Cache service also has an option to define periodic refreshes (mostly used for dynamic 3rd-party scripts) and a Purge API for deeper integration. Whenever content is updated and caches are purged, the Cache service automatically pre-warms cache PoPs in regions with a lot of traffic to prevent cache misses.
With this automated approach to cache updates we keep the integration as easy as possible. The approach works great in production and can always be extended by API-initialized cache updates if necessary.
Challenge 3: Browser caching without staleness
In the previous sections we have established how we can deal with personalization and still cache HTML resources and how we enable the Cache service to detect changes and update its cache in near real time. The main open question is how can dynamic content be cached in the Browser without an API to purge it?
Standard HTTP caching is not equipped to deal with resource changing irregularly. The standard procedure with HTTP caching is:
- The client sends a request to the server.
- The server responds with a resource and attaches a
Cache-Controlheader, which contains a time-to-live (TTL). - On the way to the client, the resource is stored by caches. We distinguish between two kinds of caches:
- Invalidation-based caches which have APIs to remove (purge) content from them. This is your standard CDN or server side cache that is shared by all users. It will generally hold on to your cache entry until the TTL expires but you can send purge requests to evict cache entries immediately.
- Expiration-based caches that hold on to resources until their TTL expires without an API to purge them. This is your client side caches like browser cache or service worker cache storage.
- On subsequent requests these caches serve the stored content as long as the TTL permits.
It is so hard to cache HTML file in the client because issues arise when the cached content changes before the TTL expires. While invalidation-based caches can be purged, expiration-based caches will continue to send stale content back to clients.
Dynamic Browser Caching: The Bloom filter-based cache sketch
Our approach is to cache all resources in the browser and set high TTL values that are dynamically estimated. So what happens when cached resources are changed before their TTL expires?
When the Cache service detects a resource change that is still cached by clients (e.g. an HTML file), it does two things:
- It purges the content in the invalidation-based cache in the CDN and backend.
- It adds the URL of the resource in a probabilistic set data structure called a counting Bloom filter for the remainder of the highest delivered TTL.
The counting Bloom filter is then flattened into a regular Bloom filter and transferred to every connecting client.
When the client loads a resource, the service worker first checks whether the URL is contained in the Bloom filter. If it is not, it can be safely taken from the browser cache. If it is, the worker forwards the request to the network, loads the resource from the CDN and updates the local cache with it.
The great thing about Bloom filters is that they are very compact by allowing for false positives: sometimes the Bloom filter will match a URL that was not inserted. False negatives on the other hand cannot happen — a URL that was inserted will always be matched by the Bloom filter.
To give an example of the compactness: A Bloom filter with a false positive rate of < 5% can store 20k different URLs in under 10kB. So it fits within the initial TCP congestion window and can usually be transferred to the client in a single round trip.
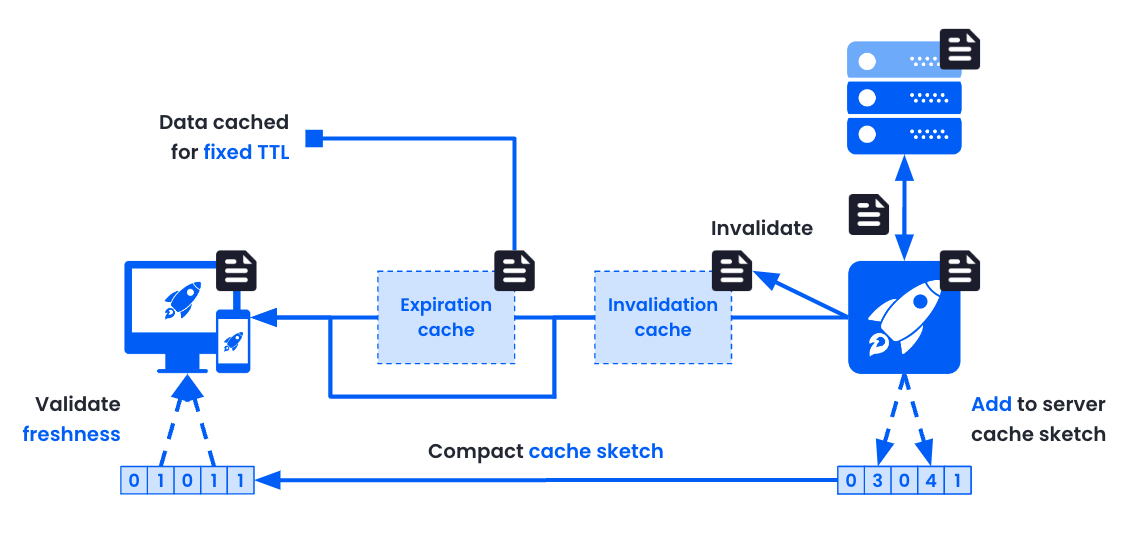
Checking for cache hits using a Bloom filter
Of course there are lots of intricate details and trade-offs involved — Bloom filter size, update cycles, TTL estimation, distributed server implementations to name a few — to make sure the performance is maximized.
Trade-offs
The way our caching approach works makes it a very powerful tool but as with any technology there are trade-offs to consider that make it more suitable on some pages compared to others.
- The way personalized content is loaded and rendered means that the biggest performance impact is on pages where the main content including the largest contentful paint (LCP) element is not personalized and can be rendered from the cached HTML. If the main content is personalized, performance is still improved by Speed Kit, but the optimization is less impactful. On e-commerce pages we therefore focus mostly on home, category and product pages and exclude fully personalized pages like cart or checkout.
- Client-side rendered sites are a nightmare when it comes to web performance with their core web vitals ranging among the worst. On those sites, the approach can struggle to achieve a large performance impact since as long a the HTML is personalized, JS execution needs to be delayed which also delays rendering of the page. On the positive side, most e-commerce pages we deal with already use server side rendering (SSR) and we are testing ways to render above the fold content on our cache servers for page that cannot migrate easily.
- First loads of a completely new user are not accelerated in this approach because the service worker needs to be installed on the first page load. It is very persistent afterwards so returning users and any navigation on the site are fully accelerated.
- Change Detection is a great technology that works extremely well in product due to an important trade off in its design. It takes one user to load a stale cache entry to detect the change and update the cache. This means that one user will see a flicker from old content to new content when the fresh document from the original server is merged. The flicker is fixed for other users and further reloads due to the change detection. In many scenarios this is a worthwhile trade-off. Content where this is not acceptable needs to be hidden until after the merge.
Advanced frontend optimizations
The use of Service Worker combined with access to Real User Monitoring (RUM) data enable other powerful optimizations:
- Predictive Preloads: RUM data enables learning algorithms to predict where the user can navigate next. This means the cached HTML can already be preloaded before the navigation. Usually servers for shop systems cannot cope with the added load of such preloads, but cache servers do not mind the extra traffic.
- 3rd-Party Caching: 3rd-party resources can be cached by the Service Worker as well to optimize their caching, save on the additional TLS connection and use a connection that already has bigger bandwidth avoiding TCP slow start for the new connection.
- Image Optimization: By running on the user’s device, the service worker has access to the screen size and DPR of the user. It attaches this information to the image requests and uses an image service to transcode, resize and recompress images automatically.
Evaluating performance with A/B tests and RUM
Of course, performance bottlenecks vary from site to site. That is why we constantly evaluate and test how this caching approach can improve performance on new websites using A/B tests and Real User Monitoring (RUM) data.
Since the integration is based on JavaScript in the client, you can easily run an A/B test to try out such a solution with 50% of users accelerated and the other 50% serving as the control group. In both group you can gather performance data with via a RUM tool.
After a few weeks of data collection, you can compare the performance between the two groups and are able to prove the significant improvements to our customers. The RUM tool also stays in place after the A/B test to monitor performance and work with our clients to achieve optimal performance in the long run.
We also use the same methodology of A/B tests with RUM tracking to research and evaluate new features and optimizations. Access to detailed RUM data from about 300 million users per month is what enabled us to perfect the approach and achieve great performance improvements.
The next graph shows an example of such an A/B test and the impact that can be achieved on websites.
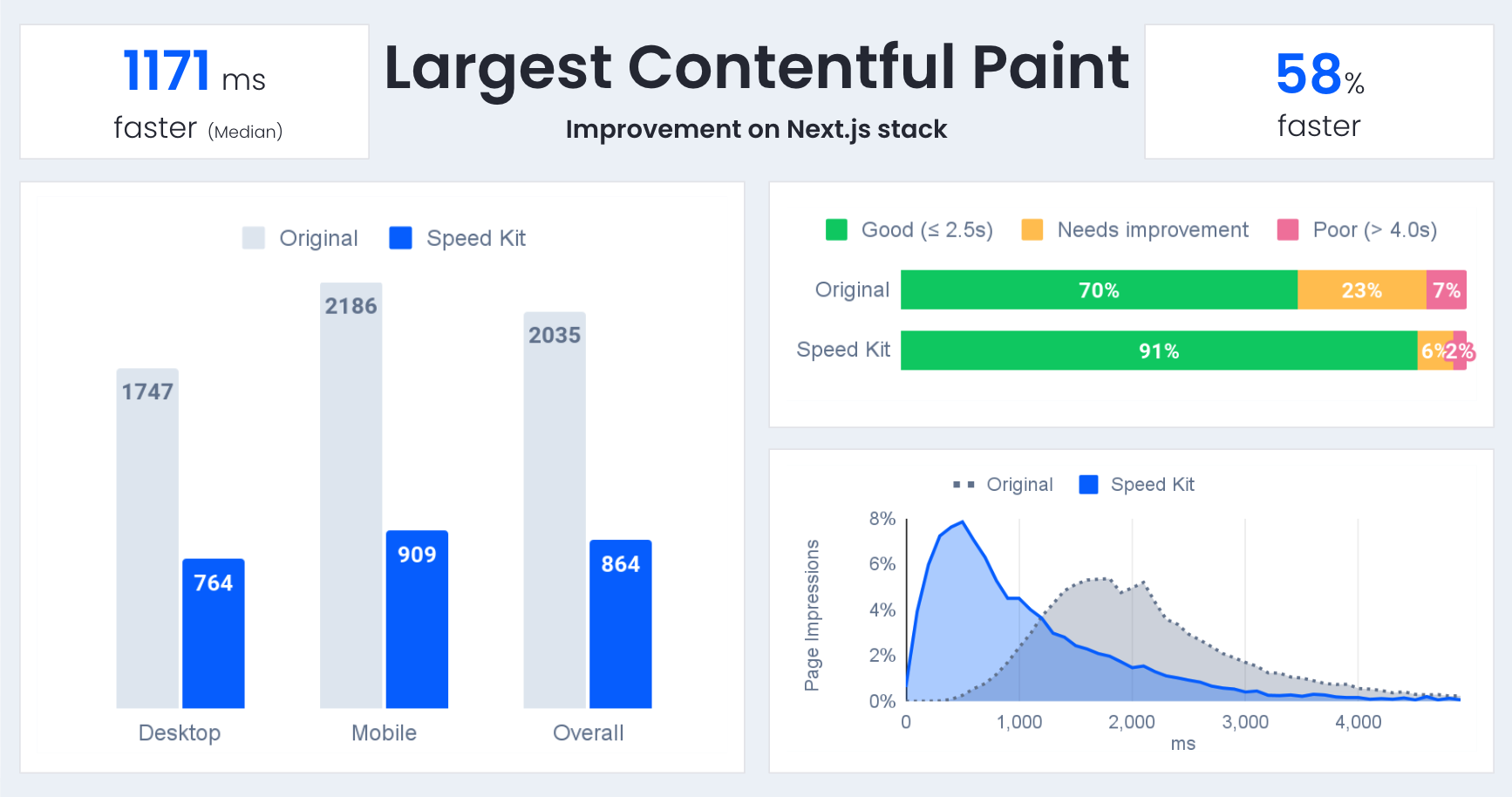
Example of an A/B test result on a product Next.js stack of a large e-commerce site.
Publications
Expand the list of publications
- Wolfram Wingerath, Benjamin Wollmer, Markus Bestehorn, Stephan Succo, Florian B�cklers, J�rn Domnik, Fabian Panse, Erik Witt, Anil Sener, Felix Gessert, and Norbert Ritter. Beaconnect: Continuous Web Performance A/B-Testing at Scale. Proceedings of the 48th International Conference on Very Large Data Bases, 2022.[ https://wolle.science/publications/wingerathbib.html#beaconnectvldb2022 | https://wolle.science/publications/wingerath-2022-vldb-beaconnect-slides.pdf | https://wolle.science/publications/wingerath-2022-vldb-beaconnect-video.mkv | https://wolle.science/publications/wingerath-2022-vldb-beaconnect.pdf | https://www.amazon.science/publications/beaconnect-continuous-web-performance-a-b-testing-at-scale ]
- Felix Kiehn, Mareike Schmidt, Daniel Glake, Fabian Panse, Wolfram Wingerath, Benjamin Wollmer, Martin Poppinga, and Norbert Ritter. Polyglot Data Management: State of the Art & Open Challenges. Proceedings of the 48th International Conference on Very Large Data Bases, 2022.[ https://vldb2022.dbis.hamburg/ | https://wolle.science/publications/wingerathbib.html#tutorialpolyglotDataManagement | https://wolle.science/publications/wingerath-2022-vldb-polyglot-data-management-tutorial-slides.pdf | https://wolle.science/publications/wingerath-2022-vldb-polyglot-data-management-tutorial.pdf ]
- Sophie Ferrlein, Wolfram Wingerath, and Benjamin Wollmer. Why Google’s CrUX Results Are Not Reproducible With Your Real-User Monitoring. Baqend Tech Blog, 2022.[ https://wolle.science/publications/wingerathbib.html#cruxvs_rum | https://medium.baqend.com/498736f82493 | https://www.youtube.com/watch?v=AMpebWYMOKw&t=792s ]
- Fabian Panse, Meike Klettke, Johannes Schildgen, and Wolfram Wingerath. Similarity-driven Schema Transformation for Test Data Generation. In Proceedings of the 25th International Conference on Extending Database Technology, EDBT 2022, Edinburgh, UK, March 29-April 1, 2022, 2022.[ https://dblp.org/rec/conf/edbt/PanseKSW22.html?view=bibtex | https://wolle.science/publications/wingerath-2022-edbt-schema-transformation.pdf ]
- Benjamin Wollmer, Wolfram Wingerath, Sophie Ferrlein, Fabian Panse, Felix Gessert, and Norbert Ritter. The Case for Cross-Entity Encoding in Web Compression. In Web Engineering – 22nd International Conference, ICWE 2022, Bari, Italy, from July 5th until July 8th, 2022. Springer, 2022.[ https://wolle.science/publications/wingerathbib.html#compazdemoencodingicwe_2022 | https://wolle.science/publications/wingerath-2022-icwe-cross-entity-delta-encoding.pdf ]
- Benjamin Wollmer, Wolfram Wingerath, Sophie Ferrlein, Felix Gessert, and Norbert Ritter. Compaz: Exploring the Potentials of Shared Dictionary Compression on the Web. In Web Engineering – 22nd International Conference, ICWE 2022, Bari, Italy, from July 5th until July 8th, 2022. Springer, 2022.[ https://wolle.science/publications/wingerathbib.html#crossentityencodingicwe_2022 | https://wolle.science/publications/wingerath-2022-icwe-compaz-demo.pdf ]
- Wolfram Wingerath, Benjamin Wollmer, Felix Gessert, Stephan Succo, and Norbert Ritter. Going for Speed: Full-Stack Performance Engineering in Modern Web-Based Applications. In Companion Proceedings of the 30th World Wide Web Conference, WWW 2021, Ljubljana, Slovenia, 2021.[ https://www2021.app.baqend.com/ | https://wolle.science/publications/wingerath-2021-www-web-tutorial-handout.pdf | https://wolle.science/publications/wingerath_bib.html#www2021tutorial | https://www2021.app.baqend.com/ | https://www2021.app.baqend.com/ | https://wolle.science/publications/wingerath-2021-www-web-tutorial.pdf | https://dl.acm.org/doi/10.1145/3442442.3453701 ]
- Wolfram Wingerath and Michaela Gebauer. Handsfree Coding: Softwareentwicklung ohne Maus und Tastatur. iX, 9:70-73, August 2021. (PDF version: https://wingerath.cloud/2021/ix).[ https://handsfree-coding.gi.de/ | https://wolle.science/publications/wingerathbib.html#ixHandsfreeCoding | https://www.youtube.com/watch?v=QRDe3IOHEA | https://wolle.science/publications/wingerath-2021-ix-handsfree-coding.pdf | https://www.heise.de/select/ix/2021/9/2028513014046345279 ]
- Fabian Panse, Andr� D�jon, Wolfram Wingerath, and Benjamin Wollmer. Generating Realistic Test Datasets for Duplicate Detection at Scale Using Historical Voter Data. In Proceedings of the 24th International Conference on Extending Database Technology, EDBT 2021, Nicosia, Cyprus, March 23-26, 2021, 2021.[ https://dblp.org/rec/conf/edbt/PanseDWW21.html?view=bibtex | https://wolle.science/publications/wingerath-2021-edbt-duplicate-detection-data.pdf ]
- Wolfram Wingerath, Benjamin Wollmer, Markus Bestehorn, Daniel Zaeh, Florian B�cklers, J�rn Domnik, Anil Sener, Stephan Succo, and Virginia Amberg. How Baqend Built a Real-Time Web Analytics Platform Using Amazon Kinesis Data Analytics for Apache Flink. AWS Big Data Blog, February 2021.[ https://wolle.science/publications/wingerathbib.html#aws2021bigDataBlogbeaconnect | https://aws.amazon.com/de/blogs/big-data/how-baqend-built-a-real-time-web-analytics-platform-using-amazon-kinesis-data-analytics-for-apache-flink/ ]
- Wolfram Wingerath, Viktor Leis, and Felix Gessert. Digitale Innovation im internationalen Vergleich – Wo steht Deutschland? GI-Radar, 296:Thema im Fokus, 2021.[ https://wolle.science/publications/wingerath_bib.html#giradar2021startups | https://gi-radar.de/296-informatik-startups/ ]
- Wolfram Wingerath, Benjamin Wollmer, and Kristian Sk�ld. Mobile Site Speed – Part 4: Measurement Best Practices. Baqend Tech Blog, 2021.[ https://wolle.science/publications/wingerathbib.html#mobileSiteSpeedpart4_measurement | https://medium.baqend.com/ff4a3f91b003 ]
- Wolfram Wingerath, Felix Gessert, and Norbert Ritter. InvaliDB: Scalable Push-Based Real-Time Queries on Top of Pull-Based Databases (Extended). Proceedings of the 46th International Conference on Very Large Data Bases, 2020.[ https://dblp.org/rec/journals/pvldb/WingerathGR20.html?view=bibtex | https://wolle.science/publications/wingerath-2020-vldb-invalidb.pdf ]
- Wolfram Wingerath, Felix Gessert, Erik Witt, Hannes Kuhlmann, Florian B�cklers, Benjamin Wollmer, and Norbert Ritter. Speed Kit: A Polyglot & GDPR-Compliant Approach For Caching Personalized Content. In 36th IEEE International Conference on Data Engineering, ICDE 2020, Dallas, Texas, April 20-24, 2020, 2020.[ https://dblp.org/rec/conf/icde/WingerathGWKBWR20.html?view=bibtex | https://wolle.science/publications/wingerath-2020-icde-speed-kit.pdf ]
- Wolfram Wingerath, Felix Gessert, and Norbert Ritter. InvaliDB: Scalable Push-Based Real-Time Queries on Top of Pull-Based Databases. In 36th IEEE International Conference on Data Engineering, ICDE 2020, Dallas, Texas, April 20-24, 2020, 2020.[ https://dblp.org/rec/conf/icde/WingerathGR20.html?view=bibtex | https://wolle.science/publications/wingerath-2020-icde-invalidb.pdf ]
- Benjamin Wollmer, Wolfram Wingerath, and Norbert Ritter. Context-aware encoding & delivery in the web. In Web Engineering – 20th International Conference, ICWE 2020, Helsinki, Finland, June 9-12, 2020, Proceedings. Springer, 2020.[ https://dblp.org/rec/conf/icwe/WollmerWR20.html?view=bibtex | https://wolle.science/publications/wingerath-2020-icwe-delta-intro.pdf ]
- Wolfram Wingerath and Benjamin Wollmer. Mobile Site Speed – Part 3: The Business Perspective. Baqend Tech Blog, 2020.[ https://wolle.science/publications/wingerathbib.html#mobileSiteSpeedpart3_business | https://medium.baqend.com/77c5852e2743 ]
- Benjamin Wollmer and Wolfram Wingerath. Mobile Site Speed – Part 2: The User Perspective. Baqend Tech Blog, 2020.[ https://wolle.science/publications/wingerathbib.html#mobileSiteSpeedpart2_user | https://medium.baqend.com/16cd77f9ce25 ]
- Wolfram Wingerath and Benjamin Wollmer. Mobile Site Speed & The Impact on Web Performance – Part 1 Intro. Baqend Tech Blog, 2020.[ https://wolle.science/publications/wingerathbib.html#mobileSiteSpeedpart1_intro | https://medium.baqend.com/54bc09ad0ba0 ]
- Wolfram Wingerath. Dynamic Cache Lifetime With Immutable Cache-Control Headers. Baqend Tech Blog, 2020.[ https://wolle.science/publications/wingerath_bib.html#dynamicCachingWithStaticHeaders | https://medium.baqend.com/db066cf60fea ]
- Stefan Puriss, Wolfram Wingerath, Thies Wrage, Kristian Sk�ld, Jan G�hmann, and Felix Gessert. The pandemic response for web performance. techreport, Baqend, October 2020.[ https://wolle.science/publications/wingerath_bib.html#2020PharmacyWhitePaper | https://wolle.science/publications/wingerath-2020-whitepaper-pandemic-response.pdf ]
- Felix Gessert, Wolfram Wingerath, and Norbert Ritter. Fast & Scalable Cloud Data Management. Springer International Publishing, 2020.[ https://link.springer.com/book/10.1007/978-3-030-43506-6 | https://dblp.org/rec/books/sp/GessertWR20.html?view=bibtex ]
- Wolfram Wingerath, Norbert Ritter, and Felix Gessert. Real-Time & Stream Data Management: Push-Based Data in Research & Practice. Springer International Publishing, 2019.[ https://link.springer.com/book/10.1007/978-3-030-10555-6 | https://dblp.org/rec/series/sbcs/WingerathRG19.html?view=bibtex ]
- Wolfram Wingerath, Felix Gessert, and Norbert Ritter. Twoogle: Searching twitter with mongodb queries. In Datenbanksysteme f�r Business, Technologie und Web (BTW), 18. Fachtagung des GI-Fachbereichs “Datenbanken und Informationssysteme” (DBIS), 4.-6.3.2019 in Hamburg, Germany. Proceedings, 2019.[ https://dblp.org/rec/conf/btw/WingerathGR19.html?view=bibtex | https://wolle.science/publications/wingerath-2019-btw-twoogle-demo.pdf ]
- Wolfram Wingerath, Felix Gessert, and Norbert Ritter. Nosql & real-time data management in research & practice. In Datenbanksysteme f�r Business, Technologie und Web (BTW 2019), 18. Fachtagung des GI-Fachbereichs ,,Datenbanken und Informationssysteme” (DBIS), 4.-8. M�rz 2019, Rostock, Germany, Workshopband, pages 267-270, 2019.[ https://dblp.org/rec/conf/btw/WingerathGR19a.html?view=bibtex | https://wolle.science/publications/wingerath-2019-btw-tutorial-nosql.pdf | https://doi.org/10.18420/btw2019-ws-28 ]
- Wolfram Wingerath and Felix Gessert. Caching the Uncacheable: How Speed Kit Accelerates E-Commerce Websites. AWS Startups Blog, October 2019.[ https://wolle.science/publications/wingerathbib.html#speedkitawsstartupblog_2019 | https://aws.amazon.com/de/blogs/startups/accelerating-ecommerce-websites-with-speed-kit/ ]
- Wolfram Wingerath. Skalierbare und Push-basierte Echtzeitanfragen f�r Pull-basierte Datenbanken. In Steffen H�lldobler, editor, Ausgezeichnete Informatikdissertationen 2019, volume D-20 of LNI. GI, 2019.[ https://dblp.org/rec/series/gidiss/Wingerath19.html?view=bibtex ]
- Wolfram Wingerath. Scalable Push-Based Real-Time Queries on Top of Pull-Based Databases. PhD thesis, University of Hamburg, 2019.[ https://dblp.org/rec/phd/dnb/Wingerath19.html?view=bibtex | https://wolle.science/publications/wingerath-2019-phd-thesis.pdf | https://invalidb.info/thesis ]
- Felix Gessert. Low Latency for Cloud Data Management. PhD thesis, University of Hamburg, 2019.[ https://dblp.org/rec/phd/dnb/Gessert19.html | https://ediss.sub.uni-hamburg.de/bitstream/ediss/8017/1/Dissertation.pdf | https://ediss.sub.uni-hamburg.de/handle/ediss/8017 ]
- Wolfram Wingerath, Felix Gessert, Erik Witt, Steffen Friedrich, and Norbert Ritter. Real-Time Data Management for Big Data. In Proceedings of the 21th International Conference on Extending Database Technology, EDBT 2018, Vienna, Austria, March 26-29, 2018. OpenProceedings.org, 2018.[ https://dblp.org/rec/conf/edbt/WingerathGWFR18.html?view=bibtex | https://wolle.science/publications/wingerath-2018-edbt-tutorial-real-time-data-management-slides.pdf | https://wolle.science/publications/wingerath-2018-edbt-tutorial-real-time-data-management.pdf ]
- Wolfram Wingerath. Web Performance Made Simple: The What, When, How, and Why in 20 Words. Baqend Tech Blog, 2018.[ https://wolle.science/publications/wingerath_bib.html#webPerformanceMadeSimple | https://medium.com/p/fc61d81d0c0e ]
- Wolfram Wingerath. Rethinking Web Performance with Service Workers: 30 Man-Years of Research in a 30-Minute Read. Baqend Tech Blog, 2018.[ https://wolle.science/publications/wingerath_bib.html#rethinkingServiceWorkers | https://medium.com/p/2638196fa60a ]
- Wolfram Wingerath, Felix Gessert, Steffen Friedrich, Erik Witt, and Norbert Ritter. The Case For Change Notifications in Pull-Based Databases. In Datenbanksysteme f�r Business, Technologie und Web (BTW 2017) – Workshopband, 2.-3. M�rz 2017, Stuttgart, Germany, 2017.[ https://dblp.org/rec/conf/btw/WingerathGFWR17.html?view=bibtex | https://wolle.science/publications/wingerath-2017-scdm-change-notifications-slides.pdf | https://wolle.science/publications/wingerath-2017-scdm-change-notifications.pdf ]
- Wolfram Wingerath. Real-Time Databases Explained: Why Meteor, RethinkDB, Parse and Firebase Don’t Scale. Baqend Tech Blog, 2017.[ https://wolle.science/publications/wingerath_bib.html#RTDBsurvey | https://www.youtube.com/watch?v=HiQgQ88AdYo | https://medium.com/p/822ff87d2f87 ]
- Wolfram Wingerath. Going Real-Time Has Just Become Easy: Baqend Real-Time Queries Hit Public Beta. Baqend Tech Blog, September 2017. Accessed: 2017-09-26.[ https://wolle.science/publications/wingerathbib.html#twoogleannouncement | http://announcement.twoogle.info/ ]
- Felix Gessert, Wolfram Wingerath, and Norbert Ritter. Scalable Data Management: An In-Depth Tutorial on NoSQL Data Stores. In Datenbanksysteme f�r Business, Technologie und Web (BTW 2017) – Workshopband, 2.-3. M�rz 2017, Stuttgart, Germany, volume P-266 of LNI, pages 399-402. GI, 2017.[ https://dblp.org/rec/conf/btw/GessertWR17.html?view=bibtex | https://wolle.science/publications/wingerath-2017-btw-tutorial-data-management-slides.pdf | https://wolle.science/publications/wingerath-2017-btw-tutorial-data-management.pdf ]
- Felix Gessert, Michael Schaarschmidt, Wolfram Wingerath, Erik Witt, Eiko Yoneki, and Norbert Ritter. Quaestor: Query Web Caching for Database-as-a-Service Providers. Proceedings of the 43rd International Conference on Very Large Data Bases, 2017.[ https://dblp.org/rec/journals/pvldb/GessertSWWYR17.html?view=bibtex | https://www.youtube.com/watch?v=JdJolwMfwF8 | https://wolle.science/publications/wingerath-2017-vldb-quaestor.pdf ]
- Steffen Friedrich, Wolfram Wingerath, and Norbert Ritter. Coordinated Omission in NoSQL Database Benchmarking. In Datenbanksysteme f�r Business, Technologie und Web (BTW 2017) – Workshopband, 2.-3. M�rz 2017, Stuttgart, Germany, 2017.[ https://dblp.org/rec/conf/btw/FriedrichWR17.html?view=bibtex | https://wolle.science/publications/wingerath-2017-scdm-coordinated-omissions-slides.pdf | https://wolle.science/publications/wingerath-2017-scdm-coordinated-omissions.pdf ]
- Wolfram Wingerath, Felix Gessert, Steffen Friedrich, and Norbert Ritter. Real-Time Stream Processing for Big Data. it – Information Technology, 58(4):186-194, 2016.[ https://dblp.org/rec/journals/it/WingerathGFR16.html?view=bibtex | https://wolle.science/publications/wingerath-2016-itit-real-time-stream-processing.pdf | http://dx.doi.org/10.1515/itit-2016-0002 ]
- Wolfram Wingerath. The Joy of Deploying Apache Storm on Docker Swarm. highscalability.com, April 2016. Accessed: 2016-05-03.[ https://wolle.science/publications/wingerath_bib.html#tutorialdocker | http://highscalability.com/blog/2016/4/25/the-joy-of-deploying-apache-storm-on-docker-swarm.html ]
- Felix Gessert, Wolfram Wingerath, Steffen Friedrich, and Norbert Ritter. NoSQL Database Systems: A Survey and Decision Guidance. Computer Science – Research and Development, 2016.[ https://dblp.org/rec/journals/ife/GessertWFR17.html?view=bibtex | https://wolle.science/publications/wingerath-2016-csrd-nosql-toolbox.pdf ]
- Thomas Seidl, Norbert Ritter, Harald Sch�ning, Kai-Uwe Sattler, Theo H�rder, Steffen Friedrich, and Wolfram Wingerath, editors. Datenbanksysteme f�r Business, Technologie und Web (BTW), 16. Fachtagung des GI-Fachbereichs “Datenbanken und Informationssysteme” (DBIS), 4.-6.3.2015 in Hamburg, Germany. Proceedings, volume 241 of LNI. GI, 2015.[ https://btw-2015.informatik.uni-hamburg.de/?startseite | https://dblp.org/rec/conf/btw/2015.html?view=bibtex | https://wolle.science/publications/wingerath-2015-btw-proceedings.pdf | http://subs.emis.de/LNI/Proceedings/Proceedings241.html ]
- Norbert Ritter, Andreas Henrich, Wolfgang Lehner, Andreas Thor, Steffen Friedrich, and Wolfram Wingerath, editors. Datenbanksysteme f�r Business, Technologie und Web (BTW 2015) – Workshopband, 2.-3. M�rz 2015, Hamburg, Germany, volume 242 of LNI. GI, 2015.[ https://btw-2015.informatik.uni-hamburg.de/?startseite | https://dblp.org/rec/conf/btw/2015w.html?view=bibtex | https://wolle.science/publications/wingerath-2015-btw-workshop-proceedings.pdf | http://subs.emis.de/LNI/Proceedings/Proceedings242.html ]
- Wolfram Wingerath, Steffen Friedrich, and Norbert Ritter. BTW 2015 – Jubil�um an der Waterkant. Datenbank-Spektrum, 15(2):159-162, 2015.[ https://dblp.org/rec/journals/dbsk/WingerathFR15.html?view=bibtex | https://wolle.science/publications/wingerath-2015-dasp-rueckblick-btw-an-der-waterkant.pdf | http://dx.doi.org/10.1007/s13222-015-0188-z ]
- Wolfram Wingerath, Steffen Friedrich, Felix Gessert, and Norbert Ritter. Who Watches the Watchmen? On the Lack of Validation in NoSQL Benchmarking. In Datenbanksysteme f�r Business, Technologie und Web (BTW), 16. Fachtagung des GI-Fachbereichs “Datenbanken und Informationssysteme” (DBIS), 4.-6.3.2015 in Hamburg, Germany. Proceedings, pages 351-360, 2015.[ https://dblp.org/rec/conf/btw/WingerathFGR15.html?view=bibtex | https://wolle.science/publications/wingerath-2015-btw-sickstore-slides.pdf | https://wolle.science/publications/wingerath-2015-btw-sickstore.pdf | http://subs.emis.de/LNI/Proceedings/Proceedings241/article20.html ]
- Felix Gessert, Michael Schaarschmidt, Wolfram Wingerath, Steffen Friedrich, and Norbert Ritter. The Cache Sketch: Revisiting Expiration-based Caching in the Age of Cloud Data Management. In Datenbanksysteme f�r Business, Technologie und Web (BTW), 16. Fachtagung des GI-Fachbereichs “Datenbanken und Informationssysteme” (DBIS), 4.-6.3.2015 in Hamburg, Germany. Proceedings, pages 53-72, 2015.[ https://dblp.org/rec/conf/btw/GessertSWFR15.html?view=bibtex | https://wolle.science/publications/wingerath-2015-btw-cache-sketch.pdf | http://subs.emis.de/LNI/Proceedings/Proceedings241/article6.html ]
- Felix Gessert, Steffen Friedrich, Wolfram Wingerath, Michael Schaarschmidt, and Norbert Ritter. Towards a Scalable and Unified REST API for Cloud Data Stores. In 44. Jahrestagung der Gesellschaft f�r Informatik, Informatik 2014, Big Data – Komplexit�t meistern, 22.-26. September 2014 in Stuttgart, Deutschland, pages 723-734, 2014.[ https://dblp.org/rec/conf/gi/GessertFWSR14.html?view=bibtex | https://wolle.science/publications/wingerath-2014-dmc-towards-scalable-rest-api.pdf | http://subs.emis.de/LNI/Proceedings/Proceedings232/article39.html ]
- Steffen Friedrich, Wolfram Wingerath, Felix Gessert, and Norbert Ritter. NoSQL OLTP Benchmarking: A Survey. In 44. Jahrestagung der Gesellschaft f�r Informatik, Informatik 2014, Big Data – Komplexit�t meistern, 22.-26. September 2014 in Stuttgart, Deutschland, pages 693-704, 2014.[ https://dblp.org/rec/conf/gi/FriedrichWGR14.html?view=bibtex | https://wolle.science/publications/wingerath-2014-dmc-oltp-benchmarking-survey-slides.pdf | https://wolle.science/publications/wingerath-2014-dmc-oltp-benchmarking-survey.pdf | http://subs.emis.de/LNI/Proceedings/Proceedings232/article216.html ]
- Fabian Panse, Wolfram Wingerath, Steffen Friedrich, and Norbert Ritter. Key-Based Blocking of Duplicates in Entity-Independent Probabilistic Data. In Proceedings of the 17th International Conference on Information Quality, IQ 2012, Paris, France, November 16-17, 2012., pages 278-296, 2012.[ https://dblp.org/rec/conf/iq/PanseWFR12.html?view=bibtex | https://wolle.science/publications/wingerath-2012-iciq-key-based-blocking.pdf ]
- Steffen Friedrich and Wolfram Wingerath. Evaluation of Tuple Matching Methods on Generated Probabilistic Data. Master’s thesis, University of Hamburg, 2012.[ https://wolle.science/publications/wingerath_bib.html#masterThesis ]
- Steffen Friedrich and Wolfram Wingerath. Search-Space Reduction Techniques for Duplicate Detection in Probabilistic Data. Master’s thesis, University of Hamburg, 2010.[ https://wolle.science/publications/wingerath_bib.html#bachelorThesis ]