

Tim Vereecke (@TimVereecke) loves speeding up websites and likes to understand the technical and business aspects of WebPerf since 15+ years. He is a web performance architect at Akamai and also runs scalemates.com: the largest (and fastest) scale modeling website on the planet.
Delivering cached HTML pages to recently logged in (=RLI) visitors is unfortunately a guarantee to frustrate users!
On websites where both guests and authenticated users navigate the same pages, a recently logged in user runs the risk of seeing anonymous content (loaded from the browser cache) and having the frustrating impression that they are logged out.
RLI Browser Cache Bypassing (RLI-BCB) completely eliminates this risk and opens the door for significant performance gains! The implementation of this technique enables aggressive settings when
- Browser-caching HTML
- Browser-prefetching HTML
- Browser-prerendering HTML
In this blog post, I explain how I implemented this technique on scalemates.com (the largest and fastest modeling website in the world). This is done by adding a query string parameter to all URLs for recently logged in users, in combination with smart use of a cookie.
RLI-BCB allowed me to implement the new Speculation Rules API, shaving off 170 ms of my LCP without frustrating my users.
I also go into some failed alternative methods and show how browsers can help solve this problem.
The Problem: Context switching
The moment your website has a logged-in area, caching HTML increases the risk of poor user experience (UX) due to context switching.
Context switching occurs when the same page is viewed both before and after a recent login: the “guest” version is loaded from the browser cache and the user thinks they are logged out.
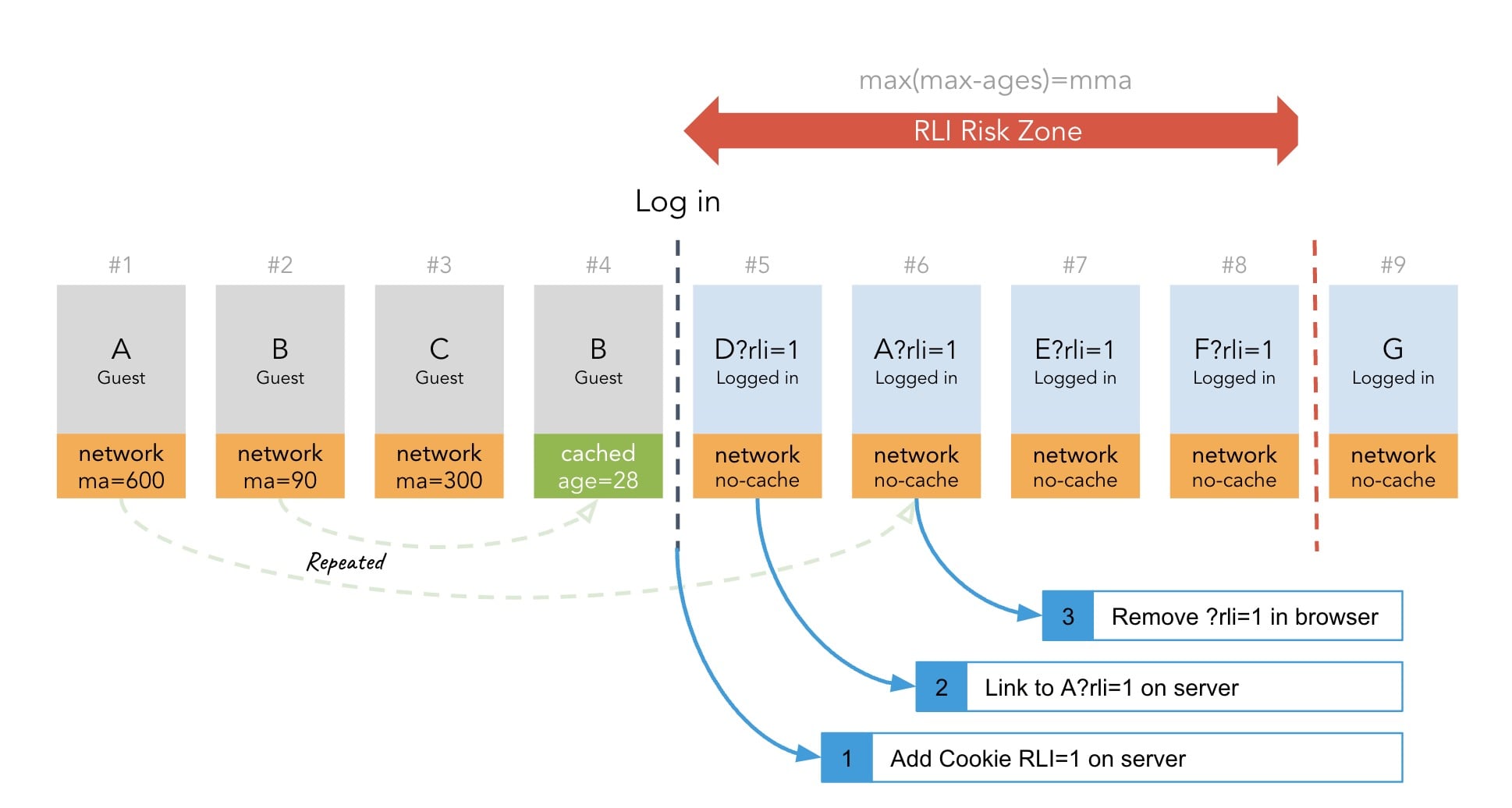
In the following diagram, we see that anonymous pages have a max-age>0 (labeled “ma=…”” in the diagram for brevity). Due to their dynamic nature authenticated pages have a cache-control set to no-cache.
We also see that page A is requested twice (#1 and #6).
- On the first request of page A (#1), before the log in, the browser cache is primed with a
cache-control: max-age=600. - Page A is requested a second time after the log in (#6, 89 seconds after #1). Page A is served directly from the browser cache.

Since the user had logged in between pages 4 and 5, they expect to see this logged in state reflected on subsequent page requests (for example, showing the username in the header, or “recently viewed items” in the sidebar).
On page 6, however, the cached “guest” version of page A is served, lacking those personalized aspects. The wrong context is displayed, giving the user the impression that they are not logged in or have been kicked out; a bad user experience.
When using the new Speculation Rules API or techniques like Instant Page, even more HTML pages are stored in the browser cache and more visitors will likely have to endure a context switch.
RLI Risk Zone
The good news is that this problem is temporary. This problem only occurs during the “RLI Risk Zone”. The RLI Risk Zone corresponds to the maximum value of your max-ages.
After this zone, the problem magically disappears, as all cached HTML content is no longer valid and new content is requested over the network.
In the following diagram we see that there are 3 different values for max-age: 90, 300 or 600 seconds. This means that after 600 s (the largest max-age value) there is no risk of context switching after login as all cached resources should have expired since login.

This means we mainly have to find a way to bridge the “RLI zone” and prevent context switches during that time.
The Solution: RLI-BCB
RLI-BCB (Recently Logged In Browser Cache Bypassing) solves this issue with the following 3 steps.
1. Identify RLI users
The moment a user logs in, the origin sets a cookie RLI=1 which is valid for the duration of the RLI Risk zone. (The RLI Risk zone duration is hardcoded here, based on my knowledge of how I configured the different max-ages for my pages.)

2. Generate Cache bypass links
During the RLI Risk zone (Cookie RLI==1) internal links receive an additional query string ?rli=1. This additional query string bypasses all existing browser cache entries (as browsers typically cache based on the entire URL, including query parameters. As such, adding a new query parameter is an easy way to do “cache busting”)
Example: An internal link to /newsfeed.php becomes /newsfeed.php?rli=1

In my implementation, the HTML page is server-side rendered, where my PHP code (I know…) reads the cookie and decides whether or not to add the rli parameter to the links.
3. Hide ?rli for users
To prevent visitors from actually ever seeing the extra query string (or sharing it with others through copy-paste), I inject an extra <script> in the HTML to update the Location Bar.
<script> history.replaceState(null, '', '/newsfeed.php'); </script>
The snippet above updates the requested ugly URL to the clean URL in the Location bar without triggering a refresh. The implemented method history.replaceState is part of the History API: a well-supported API with an adoption rate of 97%+ at the end of 2023.
Example:
A recently logged in user clicks on an RLI-BCB link fetching /kits/airfix-a11006-westland-sea-king--1495933?rli=1
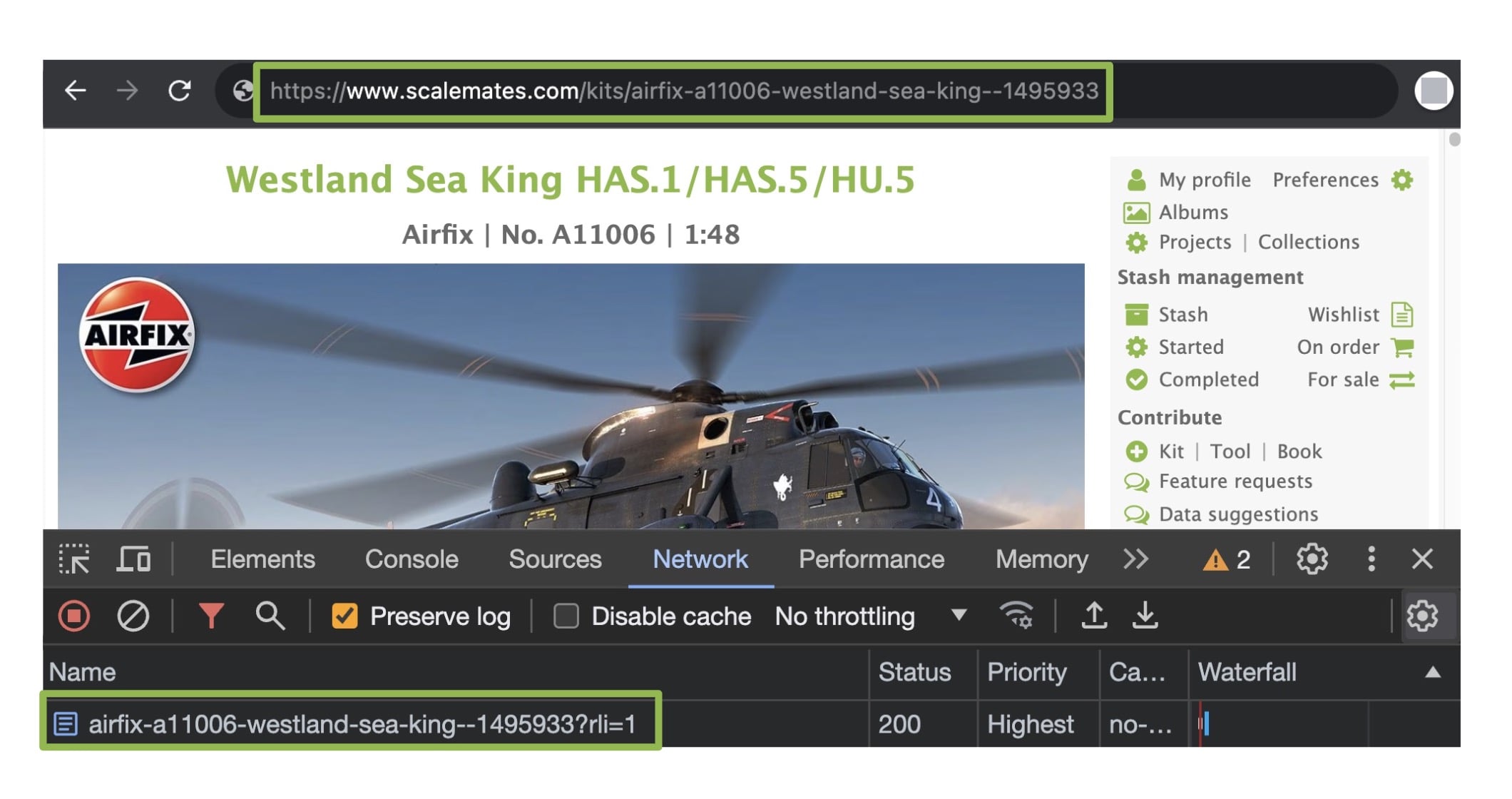
The injected script converts the RLI-BCB link in the url bar back to the original /kits/airfix-a11006-westland-sea-king--1495933

Note: A similar technique was used when I wrote about Redirect Liquidation in 2021.
Results
RLI-BCB itself does not improve performance! The technique was a prerequisite to be able to cache HTML pages in the browser for a long time and to implement the new Speculation Rules API without risking frustrated users.
My speculation rules trigger a prefetch when links are hovered (eagerness is moderate) and trigger a prerender when the user begins to interact with them (eagerness is conservative). I use CSS selectors to indicate which links should trigger the prefetch and prerender actions. These result in more HTML pages being stored in the browser cache increasing the probability of a context switch.
{
"prefetch":[{"source":"document","where":{"selector_matches":".pf, .ac a"},"eagerness":"moderate"}],
"prerender":[{"source":"document","where":{"selector_matches":".pf, .ac a"},"eagerness":"conservative"}]
}
The results of this new API are impressive:
- The P95 of LCP is around 500 ms faster
- The P75 of LCP is around 170 ms faster
- 59% of my navigations triggered pre-rendering
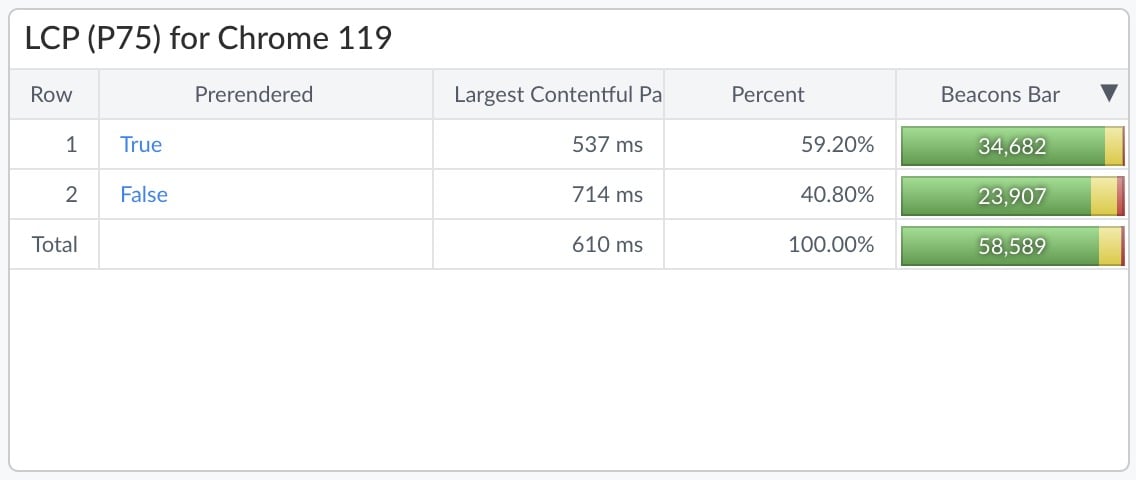
The table above shows mPulse Real User Monitoring (RUM) data for Scalemates. The Largest Contentful Paint (LCP) is 177ms faster for Prerendered pages (537 ms) compared to standard rendered pages (714 ms) at the 75th Percentile.
Failed Attempts
My solution works, but I think we all agree that it feels like a hack 😉
After reading the above, you have probably thought of a few other possibilities that sound simpler and perhaps smarter at first glance! Unfortunately, none of the next attempts on my website worked, which was what caused me to switch to the technique described above in the first place.
Vary: Cookie
Serving different content via the same URL is usually solved by using the Vary HTTP response header.
The problem with the Vary: Cookie option is that the cache is invalidated every time one of the many cookies on a website changes. On many sites this potentially happens with every other navigation (eg. Advertising cookies, security cookies, cookies tracking state,…) and leads to a similar behaviour as no-store.
In an ideal world, we would have the ability to set Vary: Cookie[name]. Vary based on a specific cookie name has been possible for many years with Akamai and other CDNs; unfortunately, it is not available to control modern browser caches (yet).
My wish for browsers in the new year: Support for Vary: Cookie[name] would make it much easier to implement HTML caching on sites with a mix of guests and authenticated users. It would also increase the adoption of speculation rules and allow everyone to cache HTML more aggressively.
Clear-Site-Data Header
The Clear-Site-Data response header clears browsing data (cookies, storage, cache) associated with the requesting website.
At first glance this was exactly what I needed: Adding Clear-Site-Data: "cache" to my login page purges the browser cache; stopping the risk of a context switch.
But there was a problem! Here you can see how First Contentful Paint (FCP) degraded on my login page after implementing this technique:
- P98: +55 s
- P95: +31 s
- P75: +1.5 s
- P50: +700 ms
Yes, that’s not a typo… a whopping 55 SECONDS at p98. Browsers apparently need a lot of time to clear their cache, as they do this in a synchronous operation. Waiting tens of seconds for the login to complete was not an acceptable solution. After reverting, the original performance immediately returned.
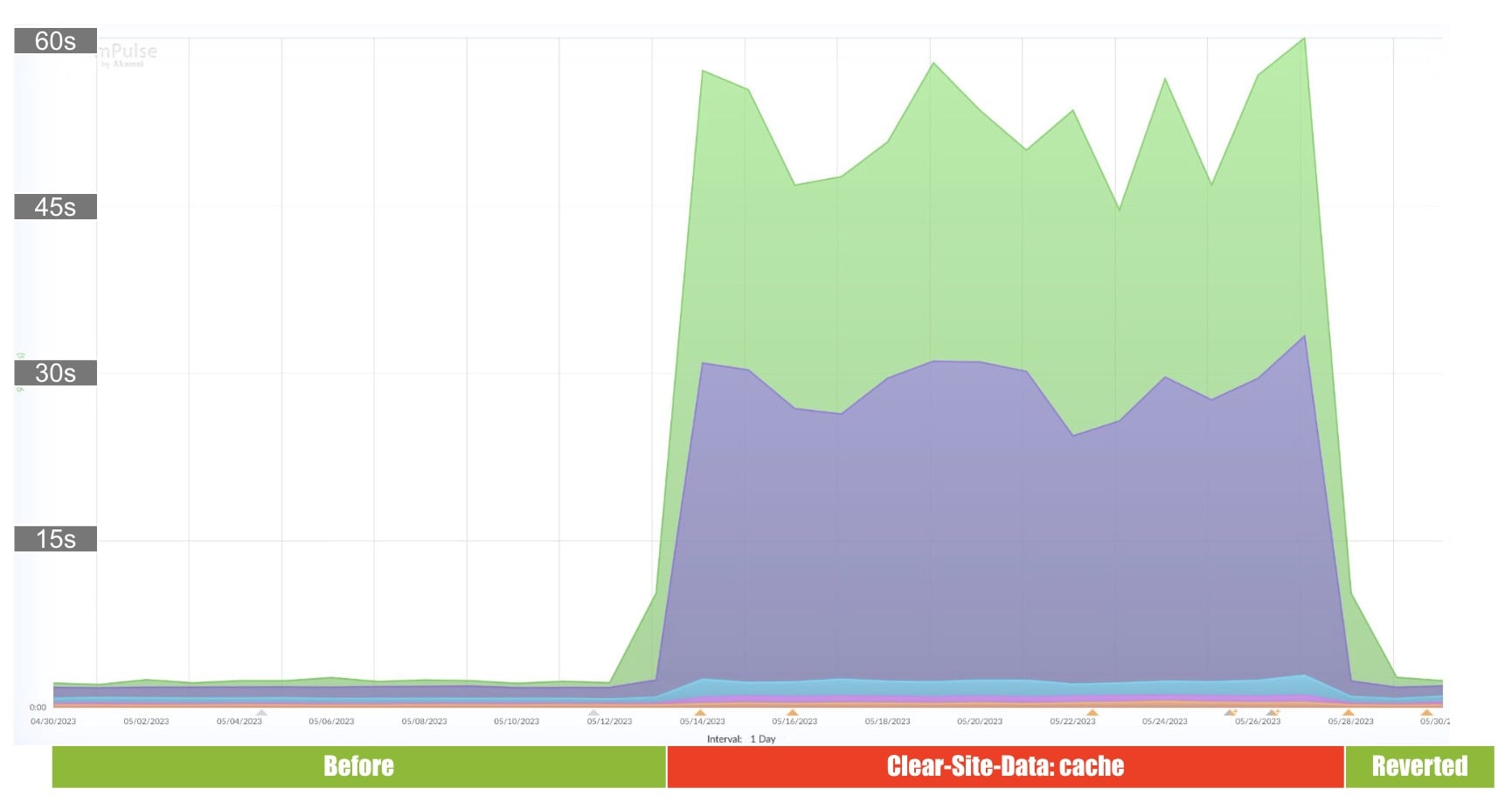
Another disadvantage of Clear-Site-Data: "cache" is that you cannot specify what to delete; it is everything or nothing. Clearing all static content will affect the performance of the next navigation(s); as static resources (CSS, JS, Fonts, etc.) will be fetched again.
Disable Caching
The easiest way to solve the problem of context switching is to deactivate browser caching.
While we remove the risk of serving the wrong context from cache, we also don’t get any performance gains from browser caching anymore though… not an ideal tradeoff.
Reduce TTL
Not quite as drastic as the complete deactivation of browser caching is the reduction of the max-age.
At some point I cached HTML for only 5 seconds. One may wonder what the likelihood is that a user will revisit the same page within this short period of time though, and what performance benefits can be expected from this setup?
Extra notes
- For the sake of simplicity, this blog post assumes that the browser cache is always faster than the network. For a more nuanced view of this topic, I recommend reading
When Network is Faster than Cache by Simon Hearne - When using the back button (and the BFcache) visitors will still see anonymous content for pages before the login.
- I implemented this at the origin as I have full control over my code. You could also implement this with for example EdgeWorkers (or similar technologies) or directly with client-side JavaScript that adds ?rli=1 to all URLs.
- You could probably also come up with a similar technique using a Service Worker.
- Many thanks to Yoav Weiss and Nicolas Hoizey for the discussions we had on this topic at We Love Speed and Performance.now().
Summary
Especially on websites where both guests and authenticated users navigate the same pages, the implementation of RLI Browser Cache Bypassing (RLI-BCB) opens the door for significant performance gains. You can cache HTML more aggressively and utilise the magic of the Speculation Rules API.
While I am happy with the results and everything is working as expected I have one wish for 2024! I wish browsers would implement Vary: Cookie[name] , which would be a standardised and much easier way to implement this common use case.
Finally, please propose an alternative name sounding better than RLI-BCB!
Thank you,
Tim Vereecke